- Wichtige Grundbegriffe und Größen (Parameter) zur Charakterisierung zufälliger oder vom Zufall beeinflußter Prozesse (z.B. Merkmal, Klassenbildung, relative Häufigkeit, Verteilung).
- Wahrscheinlichkeiten von Ereignissen: Wie wahrscheinlich ist ein Ereignis, Merkmal oder Geschehen? Nach Pearson und Neyman wird Wahrscheinlichkeit hier als Grenzwert relativer Häufigkeiten gedeutet.
- Wahrscheinlichkeiten von Hypothesen ([Bayes; Entscheidungstheorie, Justiz]): Wie wahrscheinlich sind die Hypothesen H0, H1, H2, ... ?
- Welche Repräsentationsverfahren gibt es? Wie stellt man fest, ob und wie das Repräsentationsverfahren (z.B. Zufallsauswahl) gültig ist? Wie repräsentativ ist eine Stichprobe für die betreffende Population?
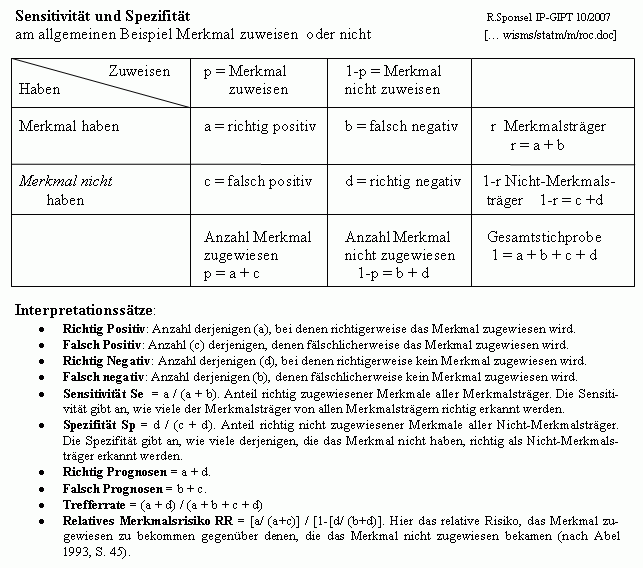
- Wahrscheinlichkeiten von Fehlern: Wie genau gilt eine statistische Aussage? Im statistischen Grundmodell gibt es immer drei Fehler- von den [vier Grundmöglichkeiten]: richtig positiv, falsch positiv, richtig negativ, falsch negativ.
- Wahrscheinlichkeiten von Gültigkeiten: wie sicher gelten unter welchen Bedingungen für wie lange statistische Aussagen? Welche Bedingungen und Voraussetzungen sind für die Gültigkeit einer statistischen Aussage wichtig? [Grundannahme-Paradoxie: Konstanz des Zufalls?]
- [Entscheidungs- und Risikomodelle]. Man entscheidet immer, ob man will oder nicht, weil auch Nichtstun oder warten als eine Entscheidung anzusehen ist. Auch das kann falsch und folgenreich sein. Bei statistischen Entscheidungen sollten deshalb die wichtigsten Sachverhalte und ihre jeweiligen Folgen berücksichtigt werden.
- Deskriptive Statistik und Einzelfallbewertung. Beispiel: Speckgürtel-Hypothesen-Untersuchung am Einzelfallbeispiel Mittelfranken 2009.
- Interpretation, empirische und praktische Bedeutung der statistischen Kennwerte. Methoden und Prüfverfahren. Dieses Feld ist das am meisten und sträflich vernachlässigte Feld.
Genauere
Operationalisierungen (Auswahl):
Klassenbildung nach Merkmalen
Statistiken werden meist über Gruppen gemacht. Eine Gruppe wird
nach einem oder mehreren Merkmalen (z.B. Alter, Geschlecht, Bildung, ...)
gebildet. Man erhält eine Gruppe also über Abstraktion durch
Merkmalsklassifikation.
Grundgesamtheiten
Die betrachtete statistische Grundgesamtheit (Masse, Kollektiv) nennt
man auch Population. Populationen können potentiell unendlich (alle
Menschen, Münzwürfe) oder endlich (alle Magenkrebskranken der
Uniklinik U im Zeitraum t) und mehr oder minder genauer bestimmt oder allgemein
sein. Es ist meist sehr wichtig, sich genau darüber klar zu werden,
über welche Population Aussagen getroffen werden sollen.
Häufigkeiten
Wie oft (h) ereignet sich E (z.B. Vulkanausbrüche, Stürme,
Hitze-/ Trockenperioden/ HIV, Magenkrebs, arbeitslos, Sterbealter usw.)
in einem Zeitraum t und in der soziokulturellen Umgebung u: h(E |
t, u)?
" | t, u" bedeute unter den Bedingungen t und u. Die Beweismethode
ist die Zählung. Nachdem das Zählen sehr aufwendig in Mühe,
Zeit und Kosten werden kann, ergibt sich sofort die nächste Beweisfrage:
Stichproben
Welche Stichprobe ist wie aussagekräftig für eine Schätzung
hs(E | t, u) für He | t, u) in der Population? Darin steckt
auch: Welche repräsentativen Stichprobenziehungen gibt es?
Verteilungen
Je nach der Anzahl und Ausprägung der in eine Verteilung eingehenden
Größen
ergeben sich unterschiedliche Verteilungsdarstellungen und daher unterschiedliche
Modelle für Verteilungen. Modell d-t-a(m) für t Meßzeitpunkte
und a Ausprägungsgrade, z.B. 1=wenig, 2=mittel, 3=viel eines Merkmals
m. Würde z.B. einmal in der Woche gemessen, wie viel es geregnet (m)
hat, so ergäben sich für ein Jahr Vv=3^52 theoretische Verteilungsmöglichkeiten.
Charakteristische
Größen
(Parameter)
Im obigen Beispiel wären charakteristische Parameter z.B. die
Anzahl der 1, 2 und 3 und der Perioden, wenn eine Periode z.B. aus einer
gleichen Anzahl besteht. Führte man einen solchen Versuch über
mehrere Jahre durch, könnte man feststellen, ob es - bezüglich
zu nennender Kriterien - Veränderungen gibt, vielleicht oder auch
nicht.
Fehlerschätzungen
Es gilt als fundamentaler Erfahrungssatz, dass alle empirischen Feststellungen
mit Fehlern behaftet sind, die sich aus vielerlei Quellen zusammensetzen,
ausgleichen, mindern oder verstärken (potenzieren) können. Zu
einer guten empirischen Theorie und Beobachtung, gehört daher auch
die Einbeziehung von Fehlern.
Zur Genauigkeit
der amtlichen Daten zum Wirtschaftswachstum
Pressemitteilung des Statistischen Bundesamtes Nr. 307
vom 3. August 2007
"WIESBADEN - Wie genau sind die Daten der deutschen amtlichen Statistik,
speziell die der Volkswirtschaftlichen Gesamtrechnungen (VGR) zum Wirtschaftswachstum?
Eine Frage, die immer wieder von Wirtschaftsforschern, Analysten und Journalisten
gestellt wird.
Berechnungen zeigen: Die laufenden Revisionen des
Bruttoinlandsprodukts (BIP) liegen in einem der hohen Aktualität angemessenen
und vertretbaren Rahmen. Im internationalen Vergleich gehören die
vierteljährlichen deutschen BIP-Berechnungen sogar zu den besten:
Nach einer Untersuchung der OECD sind die frühen Quartals-BIP-Schätzungen
der Statistikämter aus Deutschland, Frankreich und Großbritannien
die zuverlässigsten und genauesten, dicht gefolgt von denen für
die USA, Kanada und die Niederlande.
Dies ist umso bemerkenswerter, da Deutschland mit
seiner Schnellmeldung zum vierteljährlichen Bruttoinlandsprodukt (BIP)
nach nur 45 Tagen auch in punkto Aktualität zu den Spitzenreitern
in Europa zählt. Seit dem Jahr 2000 hat sich die erste Veröffentlichung
des BIP, unter anderem auf Drängen der Finanzwelt und des Bedarfs
der EZB nach aktuelleren Daten für die Eurozone, von 65 auf nur noch
45 Tage nach Abschluss des Berichtsquartals beschleunigt.
Mit der Veröffentlichung der von den Nutzern
geforderten hochaktuellen Konjunkturdaten befindet sich die amtliche Statistik
immer im Spannungsfeld zwischen Aktualität und Genauigkeit. Um möglichst
frühzeitig aktuelle Zahlen veröffentlichen zu können, werden
die
Ergebnisse auf unvollständiger Datengrundlage berechnet und zum
Teil geschätzt. Diese vorläufigen Ergebnisse werden kontinuierlich
aktualisiert, wenn neue statistische Ausgangsdaten verfügbar sind.
Darauf wird in einem eigenen Qualitätsbericht ausdrücklich hingewiesen."
Repräsentativität, Transparenz und Kontinuität statistischer Zeitreihen.
Zeitreihen sind von großer Bedeutung für die Planung, Analyse, Prognose und Beeinflussung von sozio-ökonomischen Prozessen, z.B. die Erfassung der Verschuldung von Gebietskörperschaften. Voraussetzung für die angemessene Verarbeitung, Bewertung (Evaluation) der Schuldenentwicklung ist, dass die Definition der Schulden in der Zeitreihe gleich oder wenigstens vergleichbar bleibt. Falls unterschiedliche Schuldenwerte erfasst und mitgeteilt werden, ist es zwingend erforderlich, dass die Repräsentativität, Transparenz und Kontinuität der Daten gewährleistet wird. Dies ist in Deutschland seit 1995 nicht mehr der Fall, wobei sich natürlich die Frage stellt, warum die statistischen Ämter nicht für Repräsentativität, Transparenz und Kontinuität sorgen können oder wollen? Nun, es fällt auf, dass die zunehmende Intransparenz und fragliche Repräsentativität der mitgeteilten Schuldendaten durch die statistischen Landesämter einhergeht mit einer aus dem Ruder laufenden exponentiellen, zunehmend bedrohlich erscheinenden Schuldenentwicklung auf allen Ebenen der Gebietskörperschaften, besonders auch der größeren Gemeinden (Städte und Großstädte). In Bayern beispielsweise führte das zu unklaren und unzulänglichen Veröffentlichungen [71327-001r]. Dort verwendet man z.B. Spiegelstriche " - " sowohl für "0" als auch für keine Angabe oder unbekannt ("Missing Data"); weder Definition - auch nicht deren Rechtsgrundlage - noch Repräsentativität und Kontinuität werden ausgewiesen, so dass man hier die Frage stellen muss, ob dieses verwirrende Desinformation politisch gewollt ist? [L1; L2].
Tradition
mehrdeutiger und daher unsinniger Auszeichnungen in der bayerischen Statistik
Anmerkung: Der Unsinn der Vieldeutigkeit von Zeichen könnte -
auf jeden Fall in der bayerischen - Statistik sogar Tradition haben. So
wird z.B. im Statistischen Jahrbuch der Stadt Nürnberg von 1930
unten beim Inhaltsverzeichnis ausgeführt:

Ein solches Vorgehen ist wissenschaftlich und praktisch vollkommen abzulehnen. "Nicht vorhanden" ist etwas ganz anders als die Zahl 0 und gehört infolgedessen auch mit einem eigenen Zeichen versehen, und zwar zwingend eineindeutig und nicht "verodert" (wie z.B. in der Zeugenbefragung geboten). Die Zahl 0 ist natürlich kein fehlendes Datum, insbesondere nicht bei den Schulden, und gehört selbstverständlich zwingend als 0 ausgewiesen, wenn der Schuldenstand eben Null ist (das war in Bayern erfreulicherweise im Jahre 2004 bei 76 Gemeinden der Fall). Folgende Fallunterscheidungen könnten hierbei sinnvoll sein:
- MD1: Zahl liegt grundsätzlich vor, ist aber noch nicht eingetroffen; mit ihr zu rechnen ist bis TT.MM.JJJJ.
- MD2: Zahl liegt hier nicht vor, kann aber wahrscheinlich bei ... erkundet werden.
- MD3: Zahl liegt nicht vor und ist auch nicht beschaffbar.
- MD3a: Schätzmethoden sind derzeit nicht bekannt....
- MD3b: Als Schätzmethode eignet sich ...
Beispiel
MD3b: Schätzung des Gesamtschuldenstandes Nürnbergs am 31.3.1929
in Reichsmark
Im folgenden wird dargelegt, wie man den Gesamtschuldenstand
- aus Mark ("Papiermark") und Reichsmark - für 1928/29 schätzen
kann, wenn die einzubeziehenden Geldgrößen klar ausgewiesen
oder Umrechnungsformeln angegeben würden. Zunächst der Sachverhalt,
wie ihn das Statistische Jahrbuch der Stadt Nürnberg 1930
ausweist:

Man sieht hier zwei Werte in der Rubrik "Schuldenstand am Schlusse des Jahres", einmal in "M" ("Papiermark") und der andere in "RM" (Reichsmark), ohne dass erklärt würde, wie nun der Gesamtschuldenstand zu bilden ist. Das ist wenig verständlich, wenn man sich vergegenwärtigt, dass es sich um das Jahrbuch von 1930 handelt, also 6 Jahre nach der Hyperinflation und die tatsächlichen Verrechnungsdaten ja auf jeden Fall in der Kämmerei vorliegen müssen.
Für das Haushaltsjahr 1928/29 wird im Verwaltungsbericht der Stadt Nürnberg, bearbeitet im Statistischen Amt und herausgegeben vom Stadtrat 1929, S. 434 ausgeführt:

Nach diesen Mitteilungen, sollten sich Schätzungen und Umrechnungen
durchführen lassen - wenn man wüsste, wie sich die einzelnen
Finanzgrößen (Rückkauf 339949 RM; Umtausch mit Auslosungsrechten
mit 16916156 RM und Umtausch ohne Auslösungsrechte mit 104375 RM)
zu einander verhalten. Das wird aber leider nicht mitgeteilt, so dass der
Gesamtschuldenstand natürlich davon abhängt, welche Größen
in die Umrechnung "Papiermark" und Reichsmark eingehen. Man kann also rätseln,
welcher drei hier möglich erscheinenden Gesamtschuldenstände
der richtige ist:
(1) Spielten die Umtauschgrößen keine
Rolle. ergäbe sich für die Gesamtschuld am 31.3.1929 folgender
Schätzungsansatz: 140092500 / 336949 = 415.7676681, also ein Verhältnis
von 1 Reichsmark zu gerundet 416 Mark ("Papiermark").
(2) Rechnet man die Umtauschgrößen mit
ein, ergibt sich folgende Umrechnung: 140092500 / (336949 + 16916156 +
104375) = 140092500 / (17357480) = 8.071016069, also ein Verhältnis
von 1 Reichsmark zu gerundet 8 Mark ("Papiermark").
(3) Es zählt nur die Gesamtschuld in Reichsmark,
weil die Ablösen schon in die Summe eingerechnet wurden.
Dies ergibt die möglichen Gesamtschuldenbeträge:
Rechnung (1), die 140 Mill. Papiermark sind 336949 RM wert, ergäbe
88,676999 Millionen RM Gesamtschuld.
Rechnung (2), die 140 Mill. Papiermark sind 17,357480 Mill. Reichsmark
wert, ergäbe 105,697530 Millionen RM Gesamtschuld.
Rechnung (3), es zählt nur der mitgeteilte Schuldenstand in Reichsmark,
es bliebe wie mitgeteilt, 88,340050 Millionen RM Gesamtschuld.
Veränderungen
der Erhebung statistischer Kenngrößen 1973 und 1978 am Beispiel
Verschuldung der Gemeinden
Den folgenden Ausführungen aus "Statistisches Jahrbuch Deutscher
Gemeinden", 66. Jahrgang, 1979, S. 438 kann man entnehmen, dass die Erfassungsmerkmale
der Schulden "eine Anknüpfung an die Berichterstattung bis einschließlich
1973 (61. Jahrgang) nicht mehr zu" lassen. "Im Unterschied zu 1977 sind
die Krankenhäuser nicht mehr in den Gesamtschuldenstandsbeträgen
enthalten. Sie werden wie die Eigenbetriebe nachrichtlich aufgeführt."

Was "beweist"
nun dieser wenig erfreuliche Sachverhalt ?
Nun, anscheinend ist die deutsche Statistik nicht in der Lage oder
motiviert, Sinn und Notwendigkeit vergleichbarer wichtiger sozioökonomischer
Daten, wie z.B. die Verschuldung einer Gemeinde, so zu begreifen, dass
sie die Kontinuität der Daten auch tatsächlich sicher stellen
würden. Das mag auch politisch gewollt sein, um Zusammenhänge
zu verschleiern und Transparenz und Kontinuität zu behindern.
_
Probleme
Grundannahme-Paradoxie:
Konstanz des Zufalls ?
Hier gibt es zwei Aspekte: 1) daß es so etwas wie Zufallsgesetze
überhaupt gibt; 2) inwiefern diese über die Zeit und Bedingungen
hinweg gelten ("sollen").
In der schließenden und sog. Inferenzstatistik
möchten wir nicht nur Aussagen für den Augenblick treffen, sondern
auch über statistische Regelhaftighaften von Dauer etwas erfahren,
wobei unklar ist, ob oder inwieweit "Zufall", Dauer und Konstanz einander
nicht ausschließen. Wie wollen wir Regelhaftigkeiten von Dauer erkennen,
wenn schon das einzelne Ereignis sehr unsicher ist und eine große
statistische Ereignis-Bandbreite hat?
Mathematik und
Statistik
Das Wesen mathematischer Statistik besteht auf der Basis einen strengen
Theoriegebäudes vielfach darin, die Wahrscheinlichkeit für ein
Modell M1 gegenüber einem Vergleichs- oder Kriteriums-Modell M2 oder
für Annahmen A1 gegenüber anderen Annahmen A2 zu bestimmen. Das
ist einerseits sinnvoll und ergiebig, etwa bei der Frage, ob ein empirischer
Datensatz als normalverteilt angesehen werden darf oder nicht, andererseits
sehr merkwürdig, wenn die Empirie aus einem Vergleich herausfliegt
und nur noch zwei theoretische Modelle oder hypothetische Annahmen [verglichen]
werden: Beispiel: der unselige [Signifikanztest],
der ja, kurz und bündig formuliert, nur eine statistische Aussage
unter der Annahme zuläßt, daß die Nullhypothese
richtig ist. Wir testen mit dem Signifikanztest also ein virtuelles Ergebnis.
| Denn die gewöhnliche EmpirikerIn wird meist nicht wissen wollen, was ist, wenn die Nullhypothese richtig wäre?, sondern: ist sie anzunehmen oder nicht? Welche Hypothese ist vorzuziehen, falls eine Entscheidung möglich ist ? |
Eine EmpirikerIn interessiert sich also meist nicht dafür, ob ein
Ergebnis angenommen oder verworfen werden darf, wenn die
Nullhypothese richtig ist, sondern ob sie sie annehmen oder
verwerfen soll. Die Gretchenfrage der empirischen Statistik lautet: Welche
Hypothese ist anzunehmen, die Null- oder die Alternativhypothese. Weiß
man nichts, können im Falle zweiwertiger Logik, beide Hypothesen richtig
oder falsch sein, so daß vier Fälle zu unterscheiden wären.
Das aber macht der Signifikanztest gerade nicht. Signifikanztesten scheint
also ein gigantisches Schautheater und numerologisches Zahlenspiel zu sein,
das nicht nur kaum einen Erkenntniswert hat, sondern vor allem Verwirrung
stiftet. Dafür ist die mathematische Statistik anscheinend bestens
gerüstet. Wissenschaft? Oder Wirrenschaft?
| Die großen Probleme in der Wahrscheinlichkeitsrechnung und Statistik liegen weniger in der Theorie als in der Anwendung. Es scheint so, als hätte die mathematische Statistik sich wenig um die sozialwissenschaftlichen Gegebenheiten gekümmert. Die meisten AnwenderInnen können die mathematische Statistik nicht richtig verstehen und die meisten mathematischen StatistikerInnen sind nicht in der Lage, ihre Theorien praktisch sinnvoll zu vermitteln. Theorie und Praxis driften extrem auseinander. Über weite Strecken entsteht der Eindruck, als ob nur theoretische Modell-1/ Annahme-1 gegen theoretisches Modell-2/ Annahme-2 getestet würde, wodurch wir aber nichts über die Wirklichkeit erfahren und wie wir zwischen Hypothesen entscheiden sollten. |
Statistische Paradoxien und Dilemmas nach Stegmüller
Im großen wissenschaftstheoretischen Werk Stegmüllers finden sich mehrere Kapitel oder Abschnitte, die Wahrscheinlichkeit und Statistik
Stegmüller (1973, Teil E), nennt Elf Paradoxien und Dilemmas im
Inhaltsverzeichnis:
- (1) Die Paradoxie der Erklärung des Unwahrscheinlichen (S. 281-285), z.B. 7 mal nacheinander eine 6 zu würfeln.
- (2) Das Paradoxon der irrelevanten Gesetzesspezialisierung (S. 285-286), z.B. das Problem von Scheinerklärungen zufälliger Koinzidenzen, die falsch interpretiert werden (der Mond erscheint nach einer Finsternis wieder aufgrund des großen Spektakels, das man veranstaltete).
- (3) Das Informationsdilemma. (S. 286-287), fehlende oder widersprüchliche Information mit unterschiedlichen Wahrscheinlichkeiten je nachdem, welche Merkmalskombination zugrunde gelegt wird [Partielle Korrelation]
- (4) Das Erklärungs-Bestätigungs-Dilemma (S. 287-289),
- (5) Das Paradoxon der reinen ex post facto Kausalerklärung (S. 289-291), Bestätigung und Erklärungen scheinen zirkulär und austauschbar verwendet werden können.
- (6) Das Verzahnungsparadoxon. (S. 291-295)
- (7) Das Erklärungs-Begründungs-Dilemma. (S. 295-298)
- (8) Das Dilemma der nomologischen Implikation (S. 298-299)
- (9) Das Weltanschauungsdilemma (S. 299-301)
- (10) Das Argumentationsdilemma (S. 301-303)
- (11) Das Gesetzesparadoxon. (S. 303) [analog Goodman-Paradoxon]
Die Paradoxie des statistischen Syllogismus (nach Stegmüller)

Ein schönes Beispiel und ein Fall für eine Plausibilitätsanalyse. Hier liegen zwei ganz unterschiedliche Populationen vor: In (9) die Population der Schweden und die Teilpopulationen der römisch-katholoischen Schweden und damit auch der nicht römisch-katholoischen Schweden; in (10) die Population der Lourdes Pilger und die Teilpopulation der Lourdespilger, die nicht römisch-katholischen Lourdespilger. Für eine genauere statistische Analyse wären wahrscheinlich die tatsächlichen Häufigkeitswerte interessant. Der Focus berichtet in (7) 2008 von ca. 6 Millionen jährlich. Nehmen wir an, davon sind 30.000 Schweden. Damit wären in einem Jahr (30.000/6.000.000)*100 = 0.50% Schweden dabei. Bei einem Anteil von 25% Männern bei den Besuchern wäre es dann noch 0.125%, ein Viertel von 0.50%, womit die Wahrscheinlichkeit für Petersen Lourdes Besuch bestimmt. Wenn weniger als 2% der Schweden römisch-katholisch sind
Können die beiden statistischen Schlussfolgerungen gewichtet werden?
Simpson's Paradox
Simpson fand bei bedingten Wahrscheinlichkeiten in Vierfeldertafeln einen Widerspruch dergestalt, dass bedingte Wahrscheinlichkeitsaussagen je nachdem, ob eine Gesamtbetrachtung gegenüber einer - vollständigen und disjunkten - Aufspaltung erfolgt, zu widerspruchsvollen Aussagen führen können. Solche Phänomene darf man nicht einfach nur als "Paradoxon" euphemistisch herunterspielen, sondern hier liegen tiefe und ernste Probleme in der Mathematik der Verhältnisrelationen vor, die weite Teile der angewandten Statistik-Interpretation grundsätzlich in Frage stellen, weil je nach Auswahl nicht nur unterschiedliche, sondern sogar widersprüchliche Aussagen resultieren können, wobei meist verdeckte Abhängigkeiten eine Rolle spielen, wie Székely (1990, S. 63f) ausführte, die bei der Rechnung und Interpretation nicht angemessen berücksichtigt und dargestellt werden. Das grundlegende Problem wurde von Hain & Sponsel (1994) mit dem Begriff der Relationentreue benannt, womit sich auch das Simpson'sche Paradoxon gut charakterisieren lässt, weil hier gerade eine Verletzung der Relationentreue vorliegt: Die Verhältnisrelationen von Teilen eines Ganzen sind bezüglich des Ganzen nicht relationstreu, sondern können sich sogar umkehren. Bei genauer Betrachtung stellt sich allerdings die Frage, ob in der Darstellung der sechs-Felder Tafel nicht schon im Ansatz der Fehler steckt, wenn unterschiedliche - nicht voneinander unabhängige - Teile und Ganze zu einander in Beziehung gesetzt werden, weshalb dann natürlich eine Verletzung der Relationentreue auch nicht wirklich überraschen kann. Die zahlreichen Widersprüche, Paradoxien, Absurditäten und Unverständlichkeiten in der Statistik (> Beck-Bornholdt, Székely) zeigen, dass eine gründliche Analyse, Umsicht und Skepsis gute Helfer sein können, um den zahlreichen Fallstricken und Tücken zu entgehen.

Literatur und Links zu Simpson's Paradox (Auswahl): Linksammlungen: 1, 2, 3,
- Beck-Bornholdt, Hans Peter & Dubben, Hans-Hermann (1997). Der Hund, der Eier legt. Erkennen von Fehlinformationen durch Querdenken. Reinbek: Rowohlt.
- Beck-Bornholdt, Hans Peter (2005). Mit an Wahrscheinlichkeit grenzender Sicherheit : logisches Denken und Zufall. Reinbek: Rowohlt.
- Bishop, Y. M. M.; Fienberg, S. E. & Holland, P. W. (1975). Discrete Multivariate Analysis. Cambridge, Mass.: MIT Press.
- Blyth, Colin R. (1972). On Simpson's Paradox and the Sure-Thing Principle. In: Journal of the American Statistical Association. 67, Nr. 338, 1972, p. 364366.
- Dawid, A. P. (1979). Conditional Independence in Statistical Theory Journal of the Royal Statistical Society A41(1):1-31
- Fleiss, Joseph L. (2003). Statistical methods for rates and proportions. Hoboken, NJ: Wiley.
- Grams, Timm (Denkfallen und Paradoxa): Simpson's Paradoxon.
- Pearl, Judea (1999). Simpsons's Paradox: An Anatomy. University of California, 1999, p. 111. [PDF]
- Pearson K, Lee A, Bramley-Moore L. (1899). Mathematical contributions to the theory of evolution: VI Genetic (reproductive) selection: Inheritance of fertility in man, and of fecundity in thoroughbred racehorses. Philos Trans R Soc Lond A. 1899;192: 257330.
- Simpson, E. H. (1951). The Interpretation of Interaction in Contingency Tables. In: Journal of the Royal Statistical Society. Series B (Methodological) 13 (1951), Nr. 2, p. 238241.
- Stanford Encyclopedia of Philosophy: Simpson's Paradoxon (2004).
- Stevens, S. S. (1946). On the Theory of Scales of Measurement. Science Vol. 103, No. 2684, 677-680.
- Tu, Yu-Kang ; Gunnell, David & Gilthorpe, Mark S. (2008). Simpson's Paradox, Lord's Paradox, and Suppression Effects are the same phenomenon the reversal paradox. Emerg Themes Epidemiol. 2008; 5: 2. [Online]
- Wagner, C. H. (1982). Simpson's Paradox in Real Life. In: The American Statistician, 36 (1982), Nr. 1, p. 4648.
- Wikipedia: W.de, W.en. [Die Literaturangabe zu Pearson (1899) in W.de und W.en 16.4.9 ist falsch und unzulänglich]
- Yule, G. U. (1903). Notes on the theory of association of attribution in statistics. Biometrika, 2, 121-134.
Was bedeutet
ein korrelativer Zusammenhang?
Was eine Korrelation bedeutet, weiß man nicht genau ['Schein'korrelation],
es ist ein rein statistisch-artifizielles ('künstliches') Zusammenhangsmaß,
das von Erhebung zu Erhebung, und sogar innerhalb einer einzigen Erhebung
von Merkmalsraum zu Merkmalsraum sowohl ganz unterschiedliche Zahlenwerte
als auch Bedeutungen annehmen kann. Empirisch gilt meist der Satz: je nachdem
welche Variablen in die Berechnung einbezogen oder nicht einbezogen werden,
ändern sich die Korrelationskoeffizienten, und zwar möglicherweise
sehr erheblich. Beweis: [Partielle
Korrelationen].
Fehler
Stelzl, Ingeborg (1982). Fehler und Fallen der Statistik. Für Psychologen, Pädagogen und Sozialwissenschaftler. Bern: Huber.
Ungenaue Angaben und Beschreibungen (Voraussetzungen, Hypothesen, Methoden, Ergebnisse, Geltungsbereiche, Aussagekraft/Bedeutung, Verständlichkeit, Nachvollziehbarkeit, ...).
Übertragung
von Gruppenkennwerten auf die Individuen der Gruppe.
Alexandra Hake hat diesem
Fehlschluss zwei Bände gewidmet.
Grundlagen der Interpretation statistischer Daten und Modelle
Fragen: durch die verschiedenen "Paradoxa" (Simpson, Grundannahme: Konstanz des Zufalls, Stegmüller, Korrelation) stellt sich die Frage der Bedeutung statistischer Daten verschärft. Viele Paradoxien und Widersprüche verlören an Schärfe oder lösten sich auf, wenn man folgendes Hauptprinzip anerkennt und streng beachtet:
Hauptprinzip
statistischer Interpretation
| Werden bei einem statistischen Sachverhalt neue Information
hinzugenommen oder vorhandene vernachlässigt, können sich die
statistischen Sachverhalte verändern und ihre Relationentreue
verlieren.
Diese Grundidee wird auch benutzt für die Interpretation der statistischen Un/Abhängigkeit: Spielt ein statistischer Sachverhalt B für einen statistischen Sachverhalt A keine Rolle, verändert sich mit anderen Worten die Wahrscheinlichkeit für ein Ereignis A nicht, wenn man B mit hinzu nimmt, so spricht man im Hinblick von A und B von unabhängigen Ereignissen. Diese Überlegung kann man auch für die Definition statistischer Relevanz heranziehen. Eine Sachverhalt B ist für einen Sachverhalt A relevant in dem Maße, wie er A beeinflusst, d.h. durch seine An-, Abwesenheit oder so-oder-so-Beschaffenheit (Ausprägung) zu verändern in der Lage ist. Aus unterschiedlichen Voraussetzungen oder Basen, können sich unterschiedliche Folgerungen oder Wirkungen ergeben. So erscheint z.B. die Erwartung, dass sich relative Häufigkeiten additiv wie die zugrunde liegenden absoluten Zahlen verhalten irrational, wenn die Bezugsgrößen nicht gleich sind, was folgende Vierfeldertafel illustriert: A a A+a Rel%
für a bezügl. Z Rel% A bezügl. Z3 Rel% a bezügl.
A+a
|
Manipulation, tricksen, frisieren, täuschen, verdrehen, lügen, ausblenden, weglassen.
> Repräsentativität, Transparenz und Kontinuität statistischer Zeitreihen.
Ursula
von der Leyen, die Bundesagentur und die verdreht-falsche Kinder Hartz-IV
Statistik [> Politiker]
DER SPIEGEL berichtet in Nr.5, 2012, S. 14 [Online]:
"15,1 Prozent aller Kinder unter 15 Jahren in Deutschland leben von Hartz
IV. Das sind nur 1,5 Prozentpunkte weniger als noch vor fünf Jahren.
Damals wie heute lebt etwa jedes sechste Kind am Rande des Existenzminimums.
Vergangene Woche jedoch freute sich Bundes-arbeitsministerin Ursula von
der Leyen (CDU) über Zahlen der Bundesagentur für Arbeit, nach
denen im Jahr 2011 rund 257000 Kinder weniger von Sozialleistungen lebten
als noch 2006 - ein Rückgang um 13,5 Prozent. Von der Leyen sprach
triumphierend von sinkender Kinderarmut" und der Ernte dessen, was wir
in den letzten Jahren an Kraftanstrengungen unternommen haben". Die Statistik
trügt allerdings, denn seit 2006 ist auch die Gesamtzahl der unter
15-Jährigen um 750000 gesunken. Wenn es insgesamt weniger Kinder gibt,
ist es kein Wunder, dass in absoluten Zahlen auch weniger Kinder auf Hartz
IV angewiesen sind. Der Rückgang ist in großen Teilen ein demografischer
Effekt."
Die Bundesagentur ist offenbar daran interessiert,
bewusst unzulänglich bis falsche Zahlen mitzuteilen, um einen Erfolg
zu suggerieren, der sich bei genauer Analyse so gar nicht ergibt. Wie viel
tückische Absicht dahintersteckt, mag man daran ermessen, wie einfach
es doch gewesen wäre, die vier Zahlen - Anzahl Jugendliche unter 15
im Jahre 2006 und 2011, Anzahl Jugendliche, die Hartz IV 2006 und 2011
bekamen, mitzuteilen. Diese Datenmanipulationspraxis knüpft offenbar
nahtlos an die - von Erwin Bixler
aufgedeckte - Fälschungstradition der Bundesanstalt für Arbeit
an. Euphemistisches Stroh dreschen durch tricksen, verdrehen und frisieren
von Daten scheint inzwischen auch eine besondere Spezialität der Arbeitsministerin
Ursula von der Leyen zu sein.
Weitere Quellen:
SZ: http://www.news4teachers.de/2012/01/kinderarmut-geht-zuruck-aber/
Spiegel: http://www.spiegel.de/wirtschaft/soziales/0,1518,811455,00.html
Reuters: http://de.reuters.com/article/worldNews/idDEBEE80P07W20120126
destatis [404]: Bevölkerung nach Altersgruppen seit
1950. (Klassen: unter 20, 20 - 40; 40 - 60; 60 - 80; 80 und mehr)
bpb: http://www.bpb.de/wissen/X39RH6,0,0,Bev%F6lkerung_nach_Altersgruppen_und_Geschlecht.html
bpb: http://www.bpb.de/wissen/RCQ36N,0,Familienhaushalte_nach_Zahl_der_Kinder.html
Ich wollte die Sache aufklären und habe das Statistische Bundesamt, die Bundesagentur für Arbeit, das Familienministerium und das Bundesministerium für Arbeit und Soziales angeschrieben. Die Bundesagentur für Arbeit hat bis heute nicht geantwortet. Alle anderen haben schnell und informativ reagiert. Im folgenden die
Doku Kommunikation mit dem BMAS [> Ergebnis]
- (1) Von: kontaktformular@bmas.de [mailto:kontaktformular@bmas.de] Gesendet:
Montag, 6. Februar 2012 21:17. An: info@bmas.bund.de.
Cc: Rudolf-Sponsel@sgipt.org Betreff: KAV Kontakt-Email.
Betreff: Anzahl Kinder unter 15 im Jahre 2006 und 2011
Nachricht: Sehr geehrte Damen und Herren,
ich suche die Zeitreihe der Anzahlen von Kindern unter jeweils x Jahren, im vorliegenden Fall die Zahlen von 2006 und 2011 für Kinder unter 15. Ich habe auf Ihrer Seite hierzu nichts gefunden. Vielen Dank für Ihre Bearbeitung.
Mit freundlichen Grüßen: Rudolf Sponsel (Psychologe)
https://www.sgipt.org/lit/toman/famstat.htm (ISSN 1430-6972)
(2) Auf diese Anfrage erhielt ich am 7.2. folgende Antwort:
Am 07.02.2012 08:23, schrieb info@bmas.bund.de:
Sehr geehrter Herr Sponsel,
vielen Dank für Ihre E-Mail.
Das Bundesministerium für Arbeit und Soziales ist nicht der richtige
Ansprechpartner für Ihr Anliegen.
Wir schlagen Ihnen vor, sich an das Statistische Bundesamt zu wenden.
(3) Ich schrieb daraufhin am 7.2. zurück:
Hallo Kommunikationscenter, vielen Dank für Ihre Anregung. Ich
hatte schon vorher beim Statistischen Bundesamt angefragt. Die haben aber
nur die Zahlen bis 2010. Da die Bundesarbeitsministerin die Zahlen aber
bei einer Pressekonferenz* verwendet hat, muss sie ja wohl über die
Zahlen verfügen. Also sollte Ihr Haus diese Zahlen auch haben. Daher
möchte ich Sie noch einmal eindringlich bitten, sich der Sache anzunehmen.
Ich habe die Zahlen* von einem Mathematiker mehrfach nachrechnen lassen
immer mit dem Ergebnis einer Inkonsistenz.
Mit freundlichen Grüßen: Rudolf Sponsel (Psychologe)
https://www.sgipt.org/lit/toman/famstat.htm (ISSN 1430-6972)
*DER SPIEGEL berichtet in Nr. 5, 2012, S. 14 [Online*]: "15,1 Prozent
aller Kinder unter 15 Jahren in Deutschland leben von Hartz IV. Das sind
nur 1,5 Prozentpunkte weniger als noch vor fünf Jahren. Damals wie
heute lebt etwa jedes sechste Kind am Rande des Existenzminimums. Vergangene
Woche jedoch freute sich Bundesarbeitsministerin Ursula von der Leyen (CDU)
über Zahlen der Bundesagentur für Arbeit, nach denen im Jahr
2011 rund 257000 Kinder weniger von Sozialleistungen lebten als noch 2006
- ein Rückgang um 13,5 Prozent. Von der Leyen sprach triumphierend
von sinkender Kinderarmut" und der Ernte dessen, was wir in den letzten
Jahren an Kraftanstrengungen unternommen haben". Die Statistik trügt
allerdings, denn seit 2006 ist auch die Gesamtzahl der unter 15-Jährigen
um 750000 gesunken. Wenn es insgesamt weniger Kinder gibt, ist es kein
Wunder, dass in absoluten Zahlen auch weniger Kinder auf Hartz IV angewiesen
sind. Der Rückgang ist in großen Teilen ein demografischer Effekt."
(4) Am 8.2. erhielt ich die Mitteilung: Sehr geehrter Herr Sponsel, vielen Dank für Ihre E-Mail. Ihre Zuschrift wurde zur Bearbeitung und Beantwortung an ein Fachreferat weitergeleitet. Mit freundlichem Gruß
(5) Am 22.2. erhielt dann folgendes Schreiben (Name entfernt):

Ergebnis: Offenbar hält das Referat
an der Aussage fest, dass es zwischen September 2006 und September 2011
einen Rückgang um 13.5% gab, ohne zu berücksichtigen, dass die
Bezugspopulationsgröße der unter 15jährigen in der Größenordnung
von ca. einer halben Million geschrumpft ist. Die Größen der
Bezugspopulation im September 2006 und 2011 werden leider nicht mitgeteilt.
Vergleicht man die mitgeteilten Hilfequoten von 2006 (16.5%) und von 2010
(15.9%) wird ersichtlich, dass bei dem angemessenen Vergleichsmaßstab
der Quoten lediglich eine Verbesserung um 16.5 - 15.9 = 0.6% erreicht wurde.
"Als Anfang des Jahres 2005 die Anzahl der Arbeitslosen in Deutschland die Marke von fünf Millionen überschritt, war die Aufregung groß, und die Stimmung verdüsterte sich. Der Kanzler nannte diese Zahl bedrückend, obwohl er doch wie alle wusste, dass sie nur einer neuen Zählweise geschuldet war. Offenbar war es hier die Zahl selbst und nicht die dahinter liegende gesellschaftliche Realität, die die öffentliche Wahrnehmung auf sich zog und ihrerseits beeinflusste. Die Bundesregierung hätte vielleicht besser daran getan, sich ein Beispiel an der früheren britischen
Regierung Thatcher zu nehmen, die in ihrer Regierungszeit die Arbeitslosigkeit dadurch bekämpfte, dass sie sie in dreizehn aufeinander folgenden gesetzlichen Vorschriften immer weiter herunter rechnete. Wenn nur die Zahlen sinken, ist alles in Ordnung. ..."
Reallohn-Entwicklung schaltet auf negativ, doch eine Verdummungskampagne hält dagegen. "Da meldet das Statistische Bundesamt heute vollmundig die angeblich frohe Botschaft, die deutschen Reallöhne seien im vergangenen Jahr um 1 % gestiegen. Und selbst die Seriosität vorspielende ZEIT titelt: "Reallöhne im Jahr 2011 gestiegen - Trotz hoher Inflationsrate konnten die Deutschen 2011 über mehr Geld verfügen. Experten erwarten für das Jahr 2012 einen weiteren Zuwachs der Reallöhne." Nichts kann mehr in die Irre führen. Denn erstens werden hier nur die Löhne vollzeitbeschäftigter Arbeitnehmer erfaßt, womit ein großer Teil des wuchernden Niedriglohnsektors mit Teilzeitarbeit und besonders negativer Lohnentwicklung unter den Tisch fällt. Der Anteil der ausschließlich geringfügig Beschäftigten liegt derzeit besonders hoch (Abb. 17072, 17712). ... " [jj 7.2.12]
Internationale
Ausbeutung und Verletzung elementarer Menschenrechte (gestützt
von Ursula von der Leyen) [> Politiker]
Monitor beschäftigte sich in der Sendung vom 2.2.12
mit dem Thema "Ihre Armut, unsere Hemden. Wie die Bundesregierung die Billigmode
verteidigt." Hierbei ging es um die Mindeststandards, die Unternehmen
kontrollierbar abverlangt werden sollten, etwa hinsichtlich Kinderarbeit
oder Löhnen unter jedem Existenzminimum ohne jede soziale Absicherung.
Dass selbst eine Verdoppelung der Löhne nur einen geringfügigen
Mehrpreis des Endproduktes nach sich zöge, wurde an einem Beispiel
aus Bangladesch verdeutlicht: "'Bei der Verdopplung der Löhne in Bangladesch
würde sich der Einkaufspreis eines T-Shirts ungefähr um 15 bis
20 Cent erhöhen.', so Prof. Herbert Loock, Akademie für Mode
und Design, Düsseldorf . Um dem kritischen und solidarischen Verbraucher
Möglichkeiten bei der Auswahl zu geben, beabsichtigt nun die EU-Kommission
"Eine Rechtsvorschrift über die Transparenz der sozialen und ökologischen
Informationen zu erlassen. "Im Klartext: Unternehmen müssen ihre
Produktions- und Lieferketten offenlegen. Dazu beabsichtigt die Kommission:
Zitat: "zu überprüfen, ob Unternehmen den von ihnen eingegangenen
Verpflichtungen nachgekommen sind." Doch ausgerechnet die Bundesregierung
lehnt die EU-Initiative rigoros ab. Richard Howitt ist Berichterstatter
des EU-Parlamentes für die soziale Verantwortung von Unternehmen.
Wie bewertet er die Ablehnung der Deutschen? Richard Howitt, EU-Parlament
Berichterstatter für soziale Standards (Übersetzung MONITOR):
"Ich bin sehr enttäuscht über die deutsche Haltung. Kaum war
die neue Strategie veröffentlicht, kam die Ablehnung. Vor allem gegen
unsere zentralen Vorschläge zur Modernisierung und Veränderung
der Standards unternehmerischer Verantwortung." Zuständig für
die soziale Verantwortung von Unternehmen ist Arbeitsministerin Ursula
von der Leyen. Wir fragen nach. Reporterin: "Warum blockieren Sie und Ihr
Ministerium denn hier die EU-Strategie, die eben nicht nur auf Freiwilligkeit
basieren soll?"
Ursula von der Leyen: "Ich finde, dass es ganz wichtig
ist, die soziale Verantwortung von Unternehmen zu diskutieren. Insofern
sind wir im Augenblick mit der EU-Kommission in Diskussionen darüber,
für welche Bereiche es Berichtspflichten geben soll oder auch nicht.
Die Diskussion ist noch offen."
Offen? In einem Schreiben an die EU Kommission,
das MONITOR vorliegt, spricht sich die Bundesregierung ausdrücklich
Zitat: "Gegen neue gesetzliche Berichtspflichten aus." Und weiter
unten heißt es unmissverständlich Zitat: "Das Prinzip der Freiwilligkeit
muss gewahrt bleiben."
Reporterin: "Aber in Ihrem Positionspapier haben
Sie sich doch ganz stark gegen eine gesetzliche Berichtspflichten ausgesprochen?"
Ursula von der Leyen: "Wir sind mit der EU-Kommission genau darüber
in Diskussion. Also ich sage Ihnen hier als Ministerin, dass ich offen
bin für den Dialog."
Die Recherche und Dokumentation von Monitor zeigt
klar und unmissverständlich auf, dass Arbeitsministerin Ursula von
der Leyen schriftliche und überprüfbare Tatsachen einfach wegleugnet.
Das ist eine weitverbreitete und beliebte Methode in der Politik.
_
Glossar: Wahrscheinlichkeit und Statistik: Messen, Schätzen, Testen, Schliessen. (Stichwortsammlung)
Querverweis: Elemente wissenschaftlicher und sachlicher Texte. Kleines Wissenschaftsvokabular und -Glossar mit Signierungsvorschlägen.
__
Abduktion * Abhängigkeit * Abweichung * Additiv-verbundene Messung * Alpha-Fehler * Alternativhypothese(n) * Antinomie * ANOVA * A posteriori Wahrscheinlichkeit * a priori - a posterori - Ding an sich * A priori Wahrscheinlichkeit * AR * ARCH * ARIMA-Prozess * ARMA * AUC * Ausgleichsrechnung * Ausschließen * Auswahl, Auswahlverfahren * Autokorrelation * Bayes Theorem * Bayesianer * Bedeutungsamkeitsproblem * Bedingungen * Bedingte Wahrscheinlichkeit * Bestimmtheitsmaß > Determinationskoeffizient. * Beta-Fehler * Binominalverteilung * Biplot*Conjoint measurement * cum hoc ergo propter hoc * cut off Werte * Darstellung statistischer Ergebnisse * Daten * Datentheorie * Datentyp * Datenverarbeitung * Determinationskoeffizient * Deutung statistischer Werte * Diagnostik * Diagnostische Fehlerarten * Dichte, Dichtefunktion * Differentialdiagnostik * Diskret * Diskriminanzanalyse * DNA-Test * Durchschnitt * Eindeutigkeitsproblem * Einschlusschance * Einzelfall * Entropie * Entscheidbarkeit * Entscheidung * Entscheidungstheorie * Epidemiologie * Ereignis * Ereignisalgebra (Mengenlehre) * Ergodisch, Ergodizität, Ergodensätze * Erhebungszeitraum * erklären und verstehen * Erwartungswert * Erwartungstreu(e Schätzung) * Evaluation * Evidenz * Evidenz-basierte-Medizin * Exzess * Faktorenanalyse * f * Falsch negativ * Falsch positiv * Fehler * Fehlerarten * Fiduzialkonzept * Fourier-Analyse * GARCH * Größe * Gruppenkennwert * Gültigkeitszeitraum * Häufigkeit * Heteroskedastizität * Histogramm * Homoskedastizität * Hypothese * Hypothesendiskussion * Hypothesenraum * Identifikationsanalyse * Indifferenzprinzip * Inferenz, Inferenzstatistik * Integratives Testprinzip * Interpretation statischer Größen und Ergebnisse * Intra * Inter * Inzidenz * Inzidenzenrate * IQ * Kappa * Kausalität * Kennwerte (Größen, Parameter) * Kohärenzprinzip * Kohorte * Kolmogoroff-Axiome * Kollinearität * Konnektivität, Konnexität * Konfundiert, Konfundierung * Kontingenz, kontingent * Kontinuität * Korrelation * Kovarianz * Kurtosis * Laborwertnormen * Lag * Längsschnitt-Statistik (Longitudinal) * Laplace-Experiment * Letalität * Likelihood, Likelihood Ratio, negative, positive * Logik * Longitudinal > Längsschnitt. * MA * Markovkette * Maßtheorie * Maximale Clique * Maximum-Likelihood-Methode * Median * Mengenlehre * Merkmalsraum, relevanter * Messen, Messung * Metatheorie (psychologische) * Messungen per fiat * Messfehler * Messwert, Zahlenwert * Methode * Minimum. * Mikrozensus * Missing Data * Mittel * Mittelwert ohne nähere Angabe * Mittelwert, arithmetischer * Mittelwert, geometrischer * Mittelwert, harmonischer. * Mittelwerte und Durchschnitte * Modalwert * Modell * Moderatorvariable * Moment * Morbidität * Mortalität * Multidimensionale Skalierung * Multikollinearität * Non-parametrische Statistik * Norm * Normbedingung * Normalbedingung * Normalverteilung * Normwerte * Nullhypothese * Numerologie * Nutzen * Objektivität * Objektivität, spezifische * Odds-Ratio * Ökonomie * Operationalisierung * Operationscharakteristik * Panelstudien * Parameter * Parameter-Konstanz * parametrische Verfahren. * Paranormale Fähigkeiten testen * Pfadanalyse * Plausibel/Plausibilität * Poissonverteilung * Polung. * Population. * Power, negativ prädiktive, positiv prädiktive * Prävalenz. * Praxeologie * Produkt-Moment * Prozentrang * Prüfstatistik * Quantile * Quartile * Querschnitts-Statistik * Rang, Rangzahl, Rangtests * RCT * Referenzwert * Regression, Regressionsanalyse * Relation (Beziehung) * Relationentreue * Reliabilität * Repräsentation. * Repräsentationsproblem * Risiko: * Risikokompetenz * Risikowahrscheinlichkeiten * ROC * Rohwert * Sachverhalt * Scheidewert * Schiefe * Schließende Statistik * Score * Sensitivität. * Signifikanz. * Simpson's Paradoxon * Skalierung. Messverfahren, Messmethode * Skalierungsproblem * Spannweite * Spezifität * Spiel * Spieltheorie * Spurenhypothesen * Stabil, Stabilität [numerische] * Standardabweichung * Standardbedingung * Standardnormalverteilung * Standardwert * Stanine * Statistik * Statistik, deskripve * Statistik, mathematische * Statistikpakete/ Statistikprogramme * Statistik, schließende * Statistische Hypothesen * Statistische Kennwerte * Statistisches Paradigma * Statistische Schlussweisen * Stichprobe * Stichprobenauswahlverfahren * Stichproben-Kennwerte * Stichprobenumfang * Stationär, Stationarität * Stetig * Stichprobe * Stochastik. * subjektive Wahrscheinlichkeitstheorie * Summen-Score-Funktion* Surveillance * Syllogismus, statistischer. * Telepathische Fähigkeiten * Test * Testen * Testgütekriterien. * Teststärke (Power). * Testtheorie: * Theorie * Transformation. * Transparenz. * Trennschärfe * T-Werte * unabhängig * Unsicherheit. * Unterscheiden. * Unzureichender Grund > Indifferenzprinzip * Überdiagnose-Fehler * Utilität * Validität, inkrementelle * Varianz. * Varianzanalyse * Vergleichen * verstehen * Verteilung. * Verteilungsannahmen. * Verteilungsfreie statistische Verfahren * Verteilungsfunktionen * Verteilungskennwerte * Vertrauensintervall * Vieldeutigskeitssatz. * Vorlauf-Zeit-Fehler * Voraussetzungen. * w * Wahrscheinlich, Wahrscheinlichkeit. * Wahrscheinlichkeit 1 und 2 nach Carnap * Wahrscheinlichkeit, bedingte * Wahrscheinlichkeitsbegriff Stegmüllers * Wahrscheinlichkeitsmodell. * Wahrscheinlichkeit, objektive. * Wahrscheinlichkeit, subjektive. * Wahrscheinlichkeit, totale * Welten * Wert * Wert, richtiger * Wert, wahrer * Wertzuweisung * Wette * Wissenschaftliches Arbeiten * Würfelspielparadoxon * x * Zahlen * Zeit * Zeitpunkt. * Zeitreihenanalyse * Zensus (Census) * Zentraler Grenzwertsatz * Ziel und Ziele * Zipf'sches Gesetz * Zufall * Zufallsgröße * Zureichender Grund * Zuverlässigkeit* z-Werte *
__
Abduktion Peirce (): "Abduktion ist der Vorgang, in dem eine erklärende Hypothese gebildet wird."
__
Abhaengig, Abhaengigkeit
Wichtiger und häufiger allgemeiner, wissenschaftlicher und besonders statistischer Grundbegriff. Was wie von wem abhängt ist eine der wichtigsten Fragen in der Wissenschaft. Hierzu haben die verschiedenen Wissenschaftszweige z.T. ihre eigenen Methoden entwickelt, z.T. greifen sie auf allgemeine Methoden, die von der Wissenschaftstheorie und Statistik entwickelt wurden, zurück, z.B. Datenanalyse, bedingte Wahrscheinlichkeiten, Regression, Korrelation, kanonische, partielle Korrelation. Sich ausschließende Ereignisse in der Wahrscheinlichkeitsrechnung sind abhängige Ereignisse (Rumsey 2007, S. 57).
__
Abweichung. ... von einem Bezugs-, Norm- oder Referenzwert, z. B. die Standardabweichung als Abweichungsgröße vom arithmetischen Mittelwert.
__
Additiv-verbundene Messung
__
Alpha-Fehler (Fehler erster Art). Die 0-Hypothese - z. B. A und B sind gleich - wird verworfen, obwohl sie wahr ist.
__
Alternativhypothese(n): H1, (H2, ...) Im Allgemeinen die von einer ForscherIn inhaltlich vertretene Hypothese, z.B. Lernmethode A ist für den Zweck Z "besser" als Lernmethode B. Die einseitige Nullhypothese (H0) würde dann so formuliert: A ist nicht besser, höchstens genau so gut wie B. Zweiseitig ungerichtet: A und B unterscheiden sich nicht.
Bortz (1985, S. 143) führt aus: "Grundsätzlich sollte die statistische H1 so formuliert werden, daß sie die inhaltliche Hypothese so präzise wie möglich wiedergibt. In Abhängigkeit von der Art der statistischen Hypothese ist dann ein statistisches Verfahren auszuwählen, das eine möglichst strenge" Überprüfung des hypothetisch behaupteten Sachverhaltes gewährleistet. Wir werden diese Forderung im Zusammenhang mit den einzelnen in diesem Text behandelten statistischen Verfahren erneut aufgreifen. (Ausführlicher wird das Problem des Umsetzens wissenschaftlicher Hypothesen in statistische Hypothesen bei Hager u. Westermann, 1983 diskutiert.)"
__
Antinomie.
__
ANOVA Analysis of Variance - Varianzanalyse
__
A posteriori Wahrscheinlichkeit Wahrscheinlichkeit für einen Zustand unter der Voraussetzung schon bekannter Größen und ihren Wahrscheinlichkeiten. > Bayes.
__
A priori Wahrscheinlichkeit Wahrscheinlichkeit aufgrund von Vorwissen oder per Annahme, z.V. Beispiel Gleichverteilung (fairer Würfel,. Münze), Normalverteilung, Poissonverteilung (Warteschlange), ...
__
a priori - a posterori - Ding an sich.
__
AR Autoregressives Modell. > Zeitreihenanalyse.
- Springer-Gabler definieren [A141113]:
"autoregressiver Prozess p-ter Ordnung. Ein stochastischer Prozess heißt
AR(p), wenn seine Realisation im Zeitpunkt t linear nur von seinen p gewichteten
Vergangenheitswerten und einem weißen Rauschen abhängt."
Mehr: [1, Matlab, 3,]
ARCH ARCH Autoregressives Conditionales Heteroscedastic Modell. > Zeitreihenanalyse.
__
ARIMA-Prozess Autoregressives Integrated Moving Average Modell. [ ,Matlab, ] > Zeitreihenanalyse.
__
ARMA Auto Regressive-Moving-Average. > Zeitreihenanalyse. "In der ARMA-Modellierung werden zeitliche Abhängigkeiten aufeinanderfolgender Beobachtungen analysiert." S. 16: Stroe-Kunold, Esther (2005) Multivariate Analyse instationärer Zeitreihen: Integration und Kointegration in Theorie und Simulation. Diplom-Arbeit Psychologisches Institut Heidelberg. [PDF]
[, Matlab, ]
__
AUC area under curve (Fläche unter der ROC-Kurve). Enthält auf der Ordinate (Y-Achse) die Sensitivität und auf der Abszisse (X-Achse) 1-Spezifität. Sie gibt die Trefferrate über das Verhältnis der richtig positiv vorhergesagten zu falschen falsch positiv Vorhergesagten ("falsche Alarme) an. Es gibt Werte zwischen 0 und 1. Werte um 0.5 bedeuten, es gibt so viele richtige wie falsch Vorhersagen: man könnte auch eine Münze werfen. [W]
__
Ausgleichsrechnung.
__
Ausschliessen, ausschliessbar [können, nicht]
Wichtiger und häufiger allgemeiner, wissenschaftlicher und besonders statistischer Grundbegriff.
__
Autokorrelation.
__
Auswahl, Auswahlverfahren. Vielfach können ganze Populationen nicht vermessen werden, so dass Stichprobenauswahlen erfolgen müssen. Die meisten statistischen Verfahren setzen eine Zufallsausfall voraus, wobei eine solche in den meisten Fällen nicht durchgeführt wird.
__
Bayes Theorem ...kann man auch anwenden, ohne "Bayesianer" zu sein. Grundmodell: E => H, Schluss von den Ereignissen auf die Hypothese (Frequentisten: H => E, Schluss von der Hypothese auf die Ereignisse)
__
Bayesianer Mit dieser unglücklichen Wortschöpfung - weil sie Assoziationen zum Bayes-Theorem erweckt und dieses zu diskreditieren vermag - werden die Vertreter (z.B. Keynes, Jeffrey, de Finetti, Savages) der subjektiven - im Gegensatz zur frequentistischen - Wahrscheinlichkeitsinterpretation bezeichnet. Bayesianer sollen in der deutschen Mathematik nicht gern gesehen sein. Im Gegensatz zum Bayes-Theorem, das die Wahrscheinlichkeit einer Hypothese für ein Ereignis berechnet, wenn die Ereignisse schon eingetreten sind (E => H), geht es bei den "Bayesianern" um die grundsätzliche Auffassung und Interpretation der Wahrscheinlichkeit.
Fischer, Hans (Eichstätt: 404) Vortrag: Über die richtige Art statistischen Schließens: Frequentisten gegen Bayesianer, Planetarium Nürnberg, 8.10.2013: "Soll man statistischen Schlussfolgerungen Erwartungen über zukünftige Ereignisse zugrunde legen, die man dann an den tatsächlichen Beobachtungen misst oder soll man besser ausgehend von angestellten Beobachtungen stochastische Betrachtungen vornehmen? Ein Gutteil der frühen Entwicklung der mathematischen Statistik stand unter dem Leitbild der zweitgenannten, sogenannten aposteriorischen Methoden, die von Bayes begründet wurden. Laplaces einschlägige Arbeiten bildeten zugleich einen ersten Höhepunkt dieser Entwicklung, andererseits leiteten sie aber auch einen Paradigmenwechsel hin zu apriorischen Betrachtungen ein.
Die endgültige Trendwende hin zu dem heute dominierenden, sogenannten "frequentistischen" Standpunkt wurde von R. A. Fisher und weiteren Statistikern zwischen ca. 1920 und 1935 vollzogen. Die ursprünglichen "Bayesschen" Methoden verschwanden dennoch nie vollständig und erfreuen sich heute wieder zunehmenden Interesses. Am elementaren Beispiel der "verfälschten Münzen" sollen die beiden Arten stochastischen Schließens beleuchtet, allfällige Begriffe geklärt und ein Überblick über die historische Entwicklung gegeben werden."
__
Beta-Fehler (Fehler zweiter Art). Die 0-Hypothese wird angenommen - z. B. A und B sind gleich - obwohl sie falsch ist.
__
Bedeutungsamkeitsproblem
Ausdruck der psychologischen Messtheorie. Coombs et al, S. 22: "(3) Das Bedeutsamkeitsproblem: Welche Folgerungen können aus einer bestimmten, gegebenen Meßskala gezogen werden? Welche Aussagen können aufgrund einer numerischen Meßskala sinnvollerweise gemacht werden?"
__
Bedingungen. Überhaupt, aber besonders im statistischen Bereich, elementarer Grundbegriff, der eine Erhebungssituation charakterisiert. Z.B. wird ein Lungentumor nur dann operiert, wenn er noch keine Metastasen gebildet hat. Bestimmte Test sind nur dann durchführbar, wenn eine Normalverteilung vorliegt. Andere Verfahren erfordern ein bestimmtes Skalierungsniveau oder eine Zufallsauswahl. Man spricht auch von Rand- oder Nebenbedingungen, worauf man gut verzichten kann.
__
Bedingte Wahrscheinlichkeit. Wahrscheinlichkeit für ein Ereignis E unter der Bedingung B: p(E|B).
__
Bestaetigung > Wichtiger wissenschaftlicher Grundbegriff.
__
Bestaetigungsgrad
__
Bestimmtheitsmass > Determinationskoeffizient.
__
Binominalverteilung. Wahrscheinlichkeitmodell für die zwei Ergebnismöglichkeiten in n Versuchen: Ereignis tritt für jeden Versuch mit der festen Wahrscheinlichkeit p ein ("Erfolg"), Ereignis tritt für jeden Versuch mit der festen Wahrscheinlichkeit q=1-p nicht ein ("Misserfolg"), wobei Vorgänger- und Nachfolger- Wahrscheinlichkeit voneinander unabhängig sind. Typisches Beispiel: Münzwurf mit dem Ereignis "Zahl" und "Wappen".
__
Biplot Krusche 1999, S. 34. "Biplots sind graphische Darstellungen von Datenmatrizen, die gleichzeitig Objekte und Variablen in einer Graphik abbilden (daher auch 'Bi'plots). Biplots stellen demnach nicht eine eigene Analysemethode dar, sondern bieten die Möglichkeit der Visualisierung der Zeilen und Spalten einer Datenmatrix, aufbauend auf verschiedenen dimensionserniedrigenden Verfahren (zum Beispiel der Hauptkomponentenanalyse, der mehrdimensionalen Skalierung und der Korrespondenzanalyse)." Lit:
- Gabriel, K. R. (1971). "The biplot graphic display of matrices with application to principal component analysis". Biometrika 58 (3): 453467.
- Gower, J. C. ad Hand, D. J (1996). Biplots. London: Chapman & Hall.
- Krusche, Stefan (1999). Visualisierung und Analyse multivariater Daten in der gartenbaulichen Beratung - Methodik, Einsatz und Vergleich datenanalytischer Verfahren. DISSERTATION zur Erlangung des akademischen Grades doctor rerum horticultorum (Dr. rer. hort.) Landwirtschaftlich-Gärtnerische Fakultät der Humboldt Universität zu Berlin.
- [W.eng]
Conjoint measurement verbundene Messung
Der Wert einer Variablen A wird durch den Wert der "Untervariablen" a1, a2, ... ai ...an zustande gebracht gedacht. A = f(a1, a2, ... ai ...an), im einfachsten Fall A = a1+ a2+ ... + ai + ... + an. Ich habe dieses Modell mit dem ZUF13-Versuch untersucht und weitgehend bestätigen können. Die Attraktivität (A) einer Wohnung mag abhängen von a1=Lage), a2=Größe), a3=Preis), a4=Ausstattung, a5= Stockwerk u.a.m., so dass sich A=f(a1=Lage), a2=Größe), a3=Preis), a4=Ausstattung, a5= Stockwerk).
Spektrum Lexikon der Psychologie führt aus: "verbundene Messung, conjoint measurement, die Messung von Variablen, die keine einfache Meßstruktur haben, sondern sich nur durch das additive, multiplikative oder polynomiale Zusammenwirken zweier oder mehrerer (einfach meßbarer) Einflußgrößen erklären lassen"
Quelle (Abruf 12.08.2020): https://www.spektrum.de/lexikon/psychologie/verbundene-messung/16217
__
cum hoc ergo propter hoc lat.: danach, also deshalb.
Folgt B auf A, kann A als Ursache von B angesehen werden, was falsch sein kann: dann bezeichnet der lateinische Spruch einen kausalen Fehlschluss.
__
cut off Werte. "ACOMED statistik" führt aus (071025): "Der Cut-Off-Wert ist der Wert in einem quantitativen diagnostischen Test, der zwischen zwei Testergebnissen (positiv, negativ) unterscheidet und damit einen Patienten einem der zwei untersuchten Krankheitszustände (z. B. krank vs. nicht krank oder Erkrankung 1 vs. Erkrankung 2) zuordnet. Dabei gibt immer einen Überlappungsbereich, in dem je nach Lage des Cut-Off-Punktes Patienten testpositiv oder testnegativ eingeordnet werden. Deshalb ist die Auswahl des Cut-Off-Punktes sorgfältig vorzunehmen. ..."
__
Darstellung statistischer Ergebnisse > Deutung ..., Interpretation..., Signifikanz ...,
Verständliche, in klaren deutschen Worten formulierte. inhaltliche Darstellungen sind in der Statistik - wie auch Mathematik - nicht üblich. So wirken die meisten statistischen Untersuchungsergebnisse nichtssagend und im wahrsten Sinne des Wortes bedeutungslos.
__
Daten
Unklarer und vieldeutiger wissenschaftlicher und statistischer Grundbegriff. Unterscheidbarer Sachverhalt, den man erfassen oder auch zählen und somit weiterverarbeiten kann. Werden Sachverhalte in einer Reihe (Zeitreihe) gezählt, so sollten sie gleichartig sein.
Alltägliches Datum: So ist z.B. der Sachverhalt A öffnet das Fenster gleichartig zu B öffnet das Fenster, so dass man verallgemeinernd fragen kann: wie oft, wurde an dem und dem Tag das Fenster geöffnet? Hierbei bleibt unberücksichtigt, wer es geöffnet hat, wie lange es geöffnet war, zu welchem Zeitpunkt es geöffnet und geschlossen wurde und wie lange es jeweils geöffnet war u.a.m..
Astronomisches Datum: "Alle 5000 bis 7000 Jahre kommt der Komet Neowise der Erde so nah, dass er mit bloßem Auge zu sehen ist - derzeit ist es wieder soweit. «Am 23. Juli steht er der Erde am nächsten», sagt die Wissenschaftlerin Carolin Liefke vom Haus der Astronomie in Heidelberg. Dann beträgt seine Entfernung nur noch 103 Millionen Kilometer ..."
[Quelle und Abruf 12.08.2020: https://der-farang.com/de/pages/so-nah-wie-selten-komet-neowise-derzeit-mit-blossem-auge-zu-sehen]
Sprachliches Datum: "Der, die, das" sind in der deutschen Sprache
Mathematisches Datum: Kronecker soll den Ausspruch getan haben: Die Natürlichen Zahlen sind von Gott gemacht, alles andere ist Menschenwerk" (Ein anderes Datum hierzu Popper widerspricht in dem Band Alles Leben ist Problemlösen, S. 98).
Psychologisches Datum: Am Nachmittag des 12.08.2020 beschäftigte ich mich mit allgemeiner Datentheorie.
Christlich-religiöses Datum: Ob Jesus Christus im Jahr 0 unserer Zeitrechnung geboren wurden, ist strittig.
Kalendarisches Datum: Wenn es heißt 2020 n.Chr. und damit das Jahr jetzt (12.08.2020) gemeint ist, dann wurde Jesus Christus im Jahre 2020-2020 = 0 geboren.
Physikalisches Datum: Wirft man auf der Erde einen Körper in die Luft, fällt er nach einiger Zeit zu Boden.
Informatik Datum: In der Informatik bedeutet Datum das kleinste unteilbare Element des Wertebereichs eines Datentyps. (Informatik Duden 1993, S. 188).
__
Datentheorie:
Offensichtlich gibt es eine große Mengen unterschiedlicher und unterschiedlich komplexer Daten. Die Erfassung, Klassifikation und Durchdringung der Datenvielfalt ist Aufgabe der allgemeinen Datentheorie, die derzeit immer noch nicht richtig entwickelt ist. Technisch am weitesten scheint hier die Informatik.
__
Datentyp
Nachdem es sehr viele verschiedenen Daten gibt, erscheint es sinnvoll, Datentypen zu unterscheiden. Dies sollte von einer allgemeinen Datentheorie geleistet werden, was aber noch nicht so weit ist. Von der Informatik (abstrakte, konkrete; integer [natürliche Zahl], real [rationale Zahl], boolean [wahr, falsch], char [Textzeichen]) und Psychologie (Erleben, Verhalten; beobachtbar, nicht beobachtbar) sind mir Ausarbeitungen bekannt, z.B.:
Roskam, Edward E. (1983). Allgemeine Datentheorie. In: Feger, Hubert & Bredenkamp, Jürgen (1983, Hrsg.). Messen und Testen, 1-135. Enzyklopädie der Psychologie, Themenbereich B Methodologie und Methoden, Serie I Forschungsmethoden der Psychologie, Bd. 3. Göttingen: Hogrefe.
__
Datenverarbeitung
Allgemein wissenschaftlicher, informatischer und statistischer Grundbegriff. Eine wirklich allgemeine Datenverarbeitungstheorie ist mir nicht bekannt.
__
Determinationskoeffizient. Dt. auch Bestimmtheitsmaß. Der Determinationskoeffizient ist das Quadrat des Korrelationskoeffizienten. Er gibt an, welcher Varianzanteil von den korrelierten Variablen erfasst ist ("erklärt" wird). Spielt auch eine wichtige Rolle beim Kurvenfitten und dient hier zur Prüfung der Stärke oder Güte der Anpassung. Beispiel: Es steht zur Beurteilung an, ob die 7-Tage-Mittelwerte der Corona-Neuinfektionen durch eine Exponentialverteilung beschreibbar sind. So sucht man gewöhnlich mit der Methode der kleinsten Quadrate diejenige Fitkurve, die die tatsächlichen Daten mit kleinster Abweichung erfassen. Als Maß für die Güte der Anpassung wird meist der Determinationskoeffizient R^2 (rsquare) herangezogen. Welche Grenze man für die "erklärte" Varianz wählt, z.B. 0.90, 0.95, 0.98, 0.99 ist in gewisser Weise willkürlich und kann letztlich jeder für sich selbst entscheiden. Die strenge Definition (jeder Zuwachs eines Nachfolgers muss größer als der Zuwachs des Vorgängers sein) ist bei dem Fit meist nicht eingehalten, er soll ja gerade die normalen oder üblichen Abweichungen neutralisieren. Exponentiell heißt hier also "tolerant" exponentiell, indem man schaut, wie gut (rsquare) sich die 7TM-Kurve durch eine exponentielle Gleichung anpassen lässt. Ausführliches Beispiel hier.
__
Deutung statistischer Werte und Ergebnisse > Interpretation..., Darstellung..., Signifikanz ...,
Deutungen statistischer Werte und Ergebnisse, insbesondere solche in klaren deutschen Worten, sind der Statistik - und Mathematik - nicht üblich.
__
Diagnostik := Liegt ein Merkmal in dieser oder jener Ausprägung vor? Hier gibt es immer zwei Fehlerarten.
__
Diagnostische Fehlerarten: 1) Ein Merkmal wird zugeschrieben, obwohl es nicht zutrifft (falsch positiv). 2) Ein Merkmal wird nicht erkannt, obwohl es zutrifft (falsch negativ). Man erkennt auf eine Diagnose, obwohl sie nicht vorliegt (falsch positiv) oder man erkennt eine Diagnose nicht, obwohl sie vorliegt (falsch negativ). Dieser Fehlertyp ist universell, so z. B. auch für die Rechtsprechung: jemand wird für eine Tat verurteilt, obwohl er sie nicht begangen hat (falsch positiv) oder er wird frei gesprochen, obwohl er die Tat begangen hat (falsch negativ). Nachdem das Recht idealistisch orientiert ist und vor allem Falsch-Positiv minimieren möchte, ergibt sich zwangsläufig, dass Falsch-Negativ maximiert wird, d. h. immer mehr intelligente und skrupellose TäterInnen kommen straffrei davon und durchsetzen die Gesellschaft.
__
Dichte, Dichtefunktion. Die Dichtefunktion bezieht sich auf stetige oder kontinuierliche Zufallsvariable. Sie ordnet dem Intervall, in dem sich der Wert der Zufallsvariable befindet, eine Wahrscheinlichkeit zu. Die Dichtefunktion entspricht bei diskreten Zufallsvariablen die Wahrscheinlichkeitsfunktion, die jedem der diskreten Werte, eine Wahrscheinlichkeit zuordnet. [B: 404]
__
Differentialdiagnostik := was ist es hier genau, und was nicht?
__
Diskret. Mathematischer Grundbegriff unterbrochener ("diskontinuierlicher", "unstetiger") Meßpunkte. Die 10 Millimeterstriche auf dem Metermaß sind diskret, die Strecken zwischen 1 cm und 2 cm auf dem Metermaß kontinuierlich.
__
Dimension
Wichtiger wissenschaftlicher Grundbegriff für Einteilungen und Zugehörigkeiten. Will man ordnen, stellt sich als erstes die Frage: in oder nach welcher Dimension (z.B. Zeit, Raum, Ausprägung).
__
Diskriminanzanalyse. Mathematisch-statistische Methode, ob und wie gut sich aufgrund gegebener Messwerte unterschiedliche Gruppen von einander trennen bzw. zuordnen oder klassifizieren lassen.
__
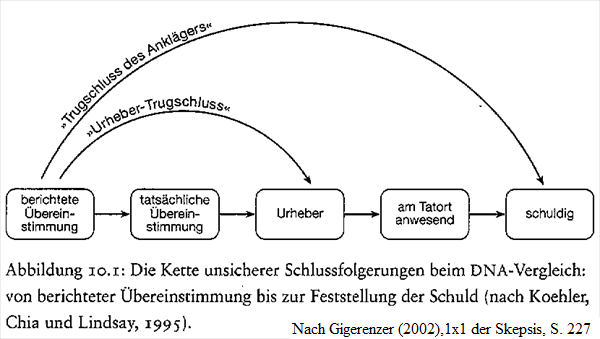
DNA-Test (auch genetischer Fingerabdruck) > Spurenhypothesen.
Er dient der Identitätsfeststellung und hat eine sehr hohe Wahrscheinlichkeit, aber er ist nicht absolut eindeutig und es gibt auch falsch positive und falsch negativ Fehler, was von manchen unkritischen forensischen Sachverständigen ausgeblendet oder gar bestritten wird.
__
Durchschnitt > Mittelwerte und Durchschnitte.
Die allgemeine Idee des Durchschnitts sind Ausprägungen in einem mittleren Bereich (> Beispiel Normalverteilung). In der Statistik und in den Sozialwissenschaften ist der "Durchschnitt" ein viel gebrauchter Begriff mit unterschiedlichen Bedeutungen. Man kann den Durchschnitt auf einen Punktwert (z.B. Mittelwert) reduzieren oder auf einen "mittleren" Wertebereich (z.B. mittlere 50% einer Verteilung zwischen 1. und 4. Quartil). Das kommt der allgemeinen Bedeutung von "mittlerer Bereich"
Die formalen Ableitungen sind gewöhnlich nicht das Problem, aber die Interpretation(en), wovor sich StatistikerInnen und MathematikerInnen erfahrungsgemäß gerne drücken. Ich habe in kaum einer Arbeit inhaltliche Aussagen in einfachen, klaren deutschen Worten zur Bedeutung der statistischen fiktiven Größen oder zu den statistischen Ergebnissen gefunden. Mittelwerte ohne Streuungsangaben und Verteilungsparameter sind problematisch. Fast immer sinnvoll ist eine graphische Darstellung der Verteilung der Zahlenwerte. Welchen Durchschnitt man nimmt, wird im allgemeinen von Zielen und Zwecken abhängen, die man mit seinem Durchschnittsanliegen verfolgt.
Verschiedene Mittelwertskonstruktionen
- Arithmetisches Mittel (Summe der Werte durch Anzahl der Werte)
- Geometrisches Mittel (n-te Wurzel des Produkts der n Zahlen; Anwendung Wachstumsraten. Mathebibel: "Das geometrische Mittel (im Gegensatz zum arithmetischen Mittel) dient zur Messung des Durchschnitts einer prozentualen Veränderung. Aus diesem Grund sagt man zum geometrischen Mittel auch durchschnittliche Veränderungsrate.")
- Gewogenes Mittel (die einzelnen Werte werden gewichtet)
- Harmonisches Mittel (Anzahl der Werte durch die Summe der Kehrwerte der Werte; Anwendung Geschwindigkeiten. Mathebibel: "Das harmonische Mittel kommt meist dann zum Einsatz, wenn der Mittelwert von Verhältniszahlen gesucht ist. Eine Verhältniszahl ist als Quotient zweier statistischer Größen definiert.")
- Hölder-Mittel (verallgemeinerter Mittelwert)
- Kubisches Mittel (3. Wurzel aus der Summe der n-Zahlenwerte dividiert durch n)
- Lehmer-Mittel (verallgemeinerter Mittelwert)
- Logarithmisches Mittel ()
- Median (Wert, der eine Zahlenreihe in zwei Hälften teilt)
- Modalwert (der Wert, der in einer Zahlenreihe am häufigsten vorkommt)
- Quadratisches Mittel (Quadratwurzel aus Summe der n quadrierten Zahlenwerte durch n)
- Stolarsky-Mittel (verallgemeinerter logarithmischer Mittelwert)
Eindeutigkeitsproblem
Ausdruck der psychologischen Messtheorie. Coombs et al, S. 21: (2) Das Eindeutigkeitsproblem: Wieviel Freiheit besteht für ein bestimmtes, gegebenes Meßverfahren in der Zuordnung von Zahlen zu Objekten? Sind die Zahlen durch den Meßvorgang eindeutig bestimmt oder sind sie willkürlich gewählt?
__
Einschlusschance
"3. Einschluss- / Ausschluss-Kriterien 3.1 Einschluss Wenn in Mischspuren alle DNA-Merkmale der fraglichen Person durchgängig nachweisbar sind, dann kommt diese Person als Spurenmitverursacher in Betracht. 3.2 Ausschluss Wenn in Mischspuren DNA-Merkmale der fraglichen Person nicht nachweisbar sind, kommt diese Person als Spurenmitverursacher nicht in Betracht" [Q]
__
Einzelfall. Recht, Kriminologie, Medizin, Psychologie sind auch angewandte idiographische Wissenschaften, d. h. sie machen Aussagen über ein Individuum. Hierbei ist ein großes und bislang ungelöstes Problem, wie man Erkenntnisse, die für Gruppen (Aggregate) gelten, auf den Einzelfall anwenden kann > Grundzüge einer idiographischen Wissenschaftstheorie. Man bedenke, dass in unseren Praxen, Büros, Kanzleien und Gerichten keine Stichproben und Populationen Platz nehmen, sondern individuelle Menschen.> Praxeologie, > evidenzbasierte Medizin.
Querverweise:
- Hake: Statistische Falschschlüsse Gruppe/Einzelfall.
- Nedopil: Prognosen in der Forensischen Psychiatrie.
Entropie > Information, > Redundanz.
Allgemein (Maß für "Unordnung" bzw. umgepolt der "Ordnung", Ungewißheit oder Gewissheit, Gleichverteilung oder Ungleichverteilung) wichtiger wissenschaftlicher Grundbegriff aus der Physik und Thermodynamik (Energieumwandlungen vergrößern die Entropie des Universums; Wärmetod des Universums: Clausius 1867), Biologie (Streben nach Ordnung), Wahrscheinlichkeitstheorie und Statistik (Maß für die Stabilität eines Zustands; Boltzmann 1880), Informationstheorie (Informationsdichte) und Sozialwissenschaften (Informationsmangel), in der Psychologie ("Entropie, Grad der Zufälligkeit, der in einem bestimmten System vorhanden ist; Maß für den Grad der Ungewißheit über den Ausgang eines Versuchs (Informationstheorie)" nach Spektrum Lexikon der Psychologie.)

Quelle: https://de.wikipedia.org/wiki/Entropie_(Informationstheorie)#/media/Datei:Entropy_max.png |
Der Informationsbegriff der Informations- theorie Shannons, der Nachrichtentechnik
und Kybernetik ist beschränkt weil syntaktisch; er entspricht nicht
dem gewöhnlichen Informationsbegriffs, der semantisch ist auf den
sachlichen und inhaltlichen Gehalt der Information abzielt. Wie inhaltliche
und sachliche Informationsgehalte gemessen werden können, ist bislang
nicht gelöst.
Einige Sätze aus der Informationstheorie:
|
Entscheidbarkeit. Wichtiger mathematischer Begriff aus der Beweistheorie (Turing, Halteproblem > W).
__
Entscheidung. Grundlegender Begriff für alle Systeme mit Wahlmöglichkeiten. Watzlawick postulierte für den zwischenmenschlichen Bereich, dass man nicht nicht-kommunizieren könne. Übertragen kann man sagen, dass man nicht nicht-entscheiden kann, denn nichts tun, warten, nicht-entscheiden ist paradoxerweise auch eine Entscheidung.
__
Entscheidungstheorie. [1 (Bamberg), ]
__
Epidemiologie. Inzidenz, Letalität, Morbidität, Mortalität, Prävalenz. > Grundbegriffe.
__
Ereignis. bestimmt durch Ort und Zeit (Grundbegriff).
Zu unabhängigen und sich ausschließenden Ereignissen schreibt Rumsey (2007), S.57: "Einander ausschließende Ereignisse können nicht unabhängig sein, und unabhängige Ereignisse können einander nicht ausschließen, außer mindestens eins der beiden Ereignisse ist die leere Menge."
__
Ereignisalgebra (Mengenlehre):
__
Ergodisch, Ergodizität, Ergodensätze
1931: Birkhoff: Allgemeiner Ergodensatz. Schlitthen & Streitberg (1984), S. 147:

Erhebungszeitraum. Zeitraum (Anfang - Ende) in dem eine Erhebung erfolgte.
__
erklären und verstehen [Quelle]
Verstehen ist wie die meisten Worte ein vielfältiges Homonym und hat mehrere Grundbedeutungen:
1) kommunikativ: die Worte und Aussage sprachlich verstehen;
2) verstehen der Bedeutung der Aussage: geistig nachvollziehen, begreifen;
3) emotionales verstehen: einfühlen, nacherleben können;
4) verstehen eines Zusammenhanges.
5) billigen, gut heißen.
6) verstehen als geistes- und sozialwissenschaftliche Methode
6b) im Unterschied zum naturwissenschaftlichen erklären.
Erklären hat ebenfalls unterschiedliche Bedeutungen:
1) Einen Zusammenhang erklären: was hängt wie mit wem zusammen?
2) Gründe G für einen Sachverhalt S angeben: S wird durch G erklärt.
3) Ursachen U für einen Sachverhalt S angeben: S wird durch U erklärt.
Anmerkung: Gründe und Ursachen bedeuten im sachlichen, logischen Kern das Gleiche. Im sozial- und geisteswissenschaftlichen Bereich bevorzugt man den Ausdruck "Gründe", im Naturwissenschaftlichen Bereich den Ausdruck Ursache.
Von Windelband (1894) wurde der wenig hilfreiche und scheinbare Gegensatz zwischen der nomothetischen, Gesetze und Regel suchenden, und der idiographischen, den konkreten Einzelfall verstehenden, Wissenschaft geschaffen. Dilthey (1900) stiftete den scheinbaren Gegensatz zwischen naturwissenschaftlichem Erklären und geisteswissenschaftlichem Verstehen.
In der Psychologie, Psychopathologie und Psychotherapie haben wir es in der Praxis immer mit dem Einzelfall oder einem individuellen Einzelfall-System (z.B. Familie) zu tun. Gesetzesartiges oder Regelhaftes gibt es aber nicht nur im Längsschnitt, in Entwicklung und Verlauf, sondern auch im Einzelfall. Einen prinzipiellen Gegensatz zwischen erklären und verstehen vermag ich nicht zu erkennen. Wenn jemand einen Pullover anzieht, weil ihm zu kalt ist, so können wir sinnvoll und verständlich sagen, wir erklären das Pullover anziehen mit unangenehm erlebtem Kälteempfinden, das den Grund liefert. Sagen wir, wir verstehen, dass er einen Pullover anzieht, weil ihm kalt ist, schwingt hier mit, dass wir uns einfühlen können, dass wir selbst Ähnliches schon erlebt haben. Diese Bedeutung hat sich seit Windelband und Dilthey in den Geisteswissenschaften - und seit Jaspers (1913) in der Psychopathologie - eingebürgert, so mag man sie denn so belassen; hier aber mit der Erweiterung, dass in den Sozial- und Geisteswissenschaften erklären und Erklärung sowohl erwünscht als auch möglich und zulässig sind. Die meisten dürften nicht verstehen, wie jemand auf Befehl von Stimmen einen Angehörigen umbringt, weil die allermeisten das selbst noch nie erlebt haben, aber dieser Sachverhalt taugt durchaus als Erklärung für einen Mord durch einen schizophrenen Schub. Ich werde in meinen forensischen Arbeiten diesen künstlichen und falschen Gegensatz nicht übernehmen und nicht weiter pflegen. Den Grundfragen des Verstehens gehe ich in einer anderen Arbeit nach.
Das Thema erklären und verstehen spielt auch in der Psychiatrie eine historische Rolle (Jaspers, Kehrer, Gruhle, Straus). Besonders aber in der forensischen Psychiatrie (> Beweisfragen-Fehler), wenn es z.B. darum geht, festzustellen, inwieweit die psychopathologischen Entsprechungen ("Voraussetzungen") für Einsichts-§ und Steuerungsfähigkeit§, Schuldfähigkeit§, Gefährlichkeit§ oder Wiederholungsrisiko§ vorliegen. [teilweise aus der Quelle 2.1.4] oder nicht bzw. mangels Informationen oder Daten nicht feststellbar sind.
__
Erwartungswert. Theoretisch der - immer unbekannte - wahre Mittelwert, praktisch oft der arithmetische Mittelwert als beste empirische Näherung ("richtiger Wert") für den gedachten wahren Wert.
__
Erwartungstreu(e Schätzung). Eine Schätzfunktion heißt erwartungstreu, wenn sie im Durchschnitt den richtigen Wert als besten Schätzer für den unbekannten "wahren" Wert liefert.
__
Evaluation. Den Wert einer Methode untersuchen und erweisen.
__
Evidenz. Offenkundig, offensichtlich, klar, banal, trivial, selbstverständlich.
__
Evidenz-basierte Medizin. Neuere Evaluations-Methode in der Heilkunde, die versucht, Entscheidungen durch wissenschaftliche Forschungsergebnisse zu stützen, also eine Verbindung zwischen der idiographischen (einzelfallorientierten, intra-individuellen) und nomothetischen (inter-individuell gültige empirische Gesetze und Regelhaftigkeiten) Betrachtungs- und Herangehensweise einzugehen. Anmerkung: Evidenz ist hier in der anglo-amerikanischen Bedeutung (Beweis, belegt) gemeint. Die deutsche Übersetzung suggeriert eine falsche Bedeutung.
__
Exzess (Kurtosis) := das 4. Moment, Abweichung von der Normalverteilung.
__
Faktorenanalyse.
__
f := Hier Zeichen für Fehler. In der psychologischen Testtheorie meist mit "e" (error) bezeichnet.
__
Falsch negativ := ein Merkmalsträger wird nicht erkannt.
__
Falsch positiv =: ein Nicht-Merkmalsträger wird fälschlich als Merkmalsträger identifiziert.
__
Fast sicher
Wenig überzeugender Ausdruck der mathematischen Wahrscheinlichkeitslehre für die Wahrscheinlichkeit 1 eines Ereignisses. Intuitiv und nach dem gesunden Menschenverstand würde man ein Ereignis mit Wahrscheinlichkeit 1 nicht "fast sicher", sondern sicher nennen.
__
Fast unmöglich
Wenig überzeugender Ausdruck der mathematischen Wahrscheinlichkeitslehre für die Wahrscheinlichkeit 0 eines Ereignisses. Intuitiv und nach dem gesunden Menschenverstand würde man ein Ereignis mit Wahrscheinlichkeit 0 nicht "fast unmöglich", sondern vollständig unwahrscheinlich nennen.
__
Fehler. Alles menschliche Feststellen und jede Messung ist mit einem Fehler behaftet, mag er auch noch so klein sein. Allgemein bedeutet Fehler eine Abweichung vom Zutreffenden oder für richtig Erachteten, wodurch eine subjektive Komponente entsteht, weil, z.B. in der Welt der Werte es keine Objektivität oder Intersubjektivität gibt.
| Entscheidung / Sachverhalt | Sachverhalt = wahr, richtig | Sachverhalt = falsch, unrichtig |
| Entscheidung für wahr, richtig | Entscheidung = wahr, richtig | Entscheidung = falsch, unrichtig |
| Entscheidung für falsch, unrichtig | Entscheidung = falsch, unrichtig | Entscheidung = wahr, richtig |
In der Statistik werden unter bestimmten - meist problematischen, unbekannten
oder nicht erfüllten - Annahmen, die Annahmen richtig oder falsch
geschätzt. Über die Wirklichkeit selbst erfährt dabei gewöhnlich
nichts. Aber man bewegt sich in scheinbar exakten, wenn auch virtuellen
Räumen.
__
Fehlerarten: Fehler können durch
systematische oder zufällige Störquellen, durch die Messmethode,
das Messgerät, die Eichung, Anzeige, Ablesung, Irrtümer oder
bewusste Fälschung zustande kommen.
- Fehler, absoluter. f = x - r. [> Messfehler]
- Fehler, relativer. f / Mittelwert
- Fehler, systematischer. Fehlerhafte Messmethode, fehlerhaftes Gerät, fehlerhaftes Ablesen; mangelnde Kontrolle anderer Einflüsse oder Störvariablen, z. B. leichtfertiges ungeprüftes oder ungesichertes Glauben von Angaben in sehr, sehr interessegeleiteten Situationen (Prüfungen, Bewerbungen, Aufträge erringen, Aussagen vor Gericht oder der MPU).
Fehler, zufälliger. Schwieriger statistischer Begriff, meist negativ definiert als nicht-systematisch; klein; durch viele Faktoren bedingt und Abweichungen nach beiden Richtungen, so dass ein gewisser Ausgleich bei der Mittelwertsbildung erfolgt. [> Zufall]
__
Fehler, statistische. > W; Interaktive Bestimmung Fehler 1. und 2. Art Uni-Konstanz.
__
Fiduzialkonzept. Konzept von Fisher, wonach aus den Realisationen der Zufallsvariablen Schlüsse auf die theoretische Verteilung und Ihre Parameter ohne a-priori Kenntnisse gezogen werden. Voraussetzungen: kontinuierliche Zufallsvariable, suffiziente Schätzung. Nach Dieter Rasch (1978, S. 202) hätten James (1954) und Stewart (1959) gezeigt, dass die Fiduzialfunktion nicht immer auf 1 normiert sei und daher nicht immer eine Dichtefunktion der Wahrscheinlichkeitsrechnung entspreche.
__
Fourier-Analyse Eine mathematische Wunderwaffe zur Analyse, Erzeugung und Zerlegung aus Komponenten von (Mess-) Daten (Reihen). Es gilt, dass jede beliebige Verlaufsform aus Sinuskurven konstruiert werden kann.
__
Frequentisten Name für die VertreterInnen eines Wahrscheinlichkeitsbegriff, der die relativen Häufigkeit von Ereignissen zum Dreh- und Angelpunkt der Statistik macht, z.B. Fisher, Pearson, Neyman, von Mises. Grundmodell direkter Schluss: H => E. Inverser Schluss: E => H Bayes Theorem). Grundsätzliche Gegenposition "Bayesianer",
__
GARCH Generalized ARCH > Zeitreihenanalyse.
__
Gesetz der großen Zahlen
Oskar Anderson (1954), S. 105: "4. Das Prinzip· oder Gesetz der großen Zahlen. Der Begriff des Gesetzes der großen Zahlen hat im Laufe der 120 Jahre, die nunmehr seit dem Erscheinen von Poissons Recherches (1837) verflossen sind, bedeutende Wandlungen durchgemacht, und wenn in der Fachliteratur bis heute noch keine vollständige Einmütigkeit über seinen Inhalt herrscht, so geht die allgemeine Entwicklung doch zweifellos dahin, im Anschluß an Poissons Einleitung (aber in einem gewissen Gegensatz zum weiteren Text seines Werkes) unter diesem Gesetz (oder, wie es richtiger wäre zu sagen, unter diesem Prinzip) die ganz generelle Tatsache zu verstehen, daß bei Einhaltung gewisser allgemeiner Bedingungen sehr viele statistische Kollektivmaßzahlen, die für eine Beobachtungsserie berechnet werden, im allgemeinen desto weniger von gewissen konstanten 'Grenzwerten abweichen werden, je größer der Umfang n der Serie genommen wird 11). So verstanden, ist das Prinzip der großen Zahlen jedenfalls kein Theorem der reinen Mathematik, die an und für sich keine Möglichkeit bietet, allein aus ihrem theoretischen Inhalt heraus irgendwelche Aussagen über die konkrete Tatsachenwelt bloß durch tautologische Umformungen abzuleiten. Es wäre z.B. undenkbar, nur aus den Lehrsätzen der Geometrie eine zwingende Schlußfolgerung darüber zu gewinnen, ob der tatsächliche Raum, in dem wir uns befinden, derjenige von Euklid,, Riemann oder etwa von Lobatschewskij ist l2.
Hieraus folgt aber andererseits durchaus nicht, daß das Prinzip der großen Zahlen ganz ohne Anwendung eines mathematischen Apparats begründet werden könne. Die Versuche, die in dieser Hinsicht von einer Anzahl antimathematischer (insbesondere deutscher) Statistiker gemacht worden sind, haben zu keinen wissenschaftlich verwertbaren Ergebnissen geführt: der Sinn des meistens recht wortreichen Rerumredens um dieses Prinzip bleibt dunkel und nebelhaft.
M. E. bestehen nur zwei Möglichkeiten dafür, das Prinzip der großen Zahlen logisch sauber zu begründen: entweder man nimmt wie es etwa v. Mises getan hat gewisse Beobachtungen des täglichen Geschehens in die Zahl der Axiome und Definitionen der Wahrscheinlichkeitstheorie mit hinein und leitet dann dieses Prinzip aus ihnen durch tautologische Umformungen ab, oder aber man sagt sich in der Wahrscheinlichkeitsrech-[>106]nung von jeglicher Bezugnahme auf die Tatsachenwelt von Anfang an los und üherläßt diese jenen Disziplinen, die die betreffenden Lehren praktisch anzuwenden und auszuwerten haben. Im ersten Falle gehört die Wahrscheinlichkeitstheorie zum Gebiet der angewandten Mathematik, im letzteren bleibt sie als Teil der reinen Mathematik bestehen. Die moderne Richtung in der Wahrscheinlichkeitstheorie neigt sich immer mehr zur zweiten Alternative hin. Dies bedeutet, daß man anstelle des v. Misesschen jenen Weg betreten sollte, den uns A. Coumot (1843) bereits vor 114 Jahren gewiesen hat. Dieselbe Idee wurde später von P. Mansion (1903) wieder aufgegriffen und durch das klassische Buch von A. A. Tschuprow (1910) (welches leider seinerzeit nicht ins Deutsche übersetzt worden war) im Bereiche der die russische Sprache verstehenden Welt im weitesten Maße popularisiert. In der französischen wissenschaftlichen Literatur wird derselbe Standpunkt z. B. von Frackel vertreten."
Größe. Grundlegender wissenschaftlicher
Begriff, der im allgemeinen eine quantitative (messbare) Qualität
beschreibt und mit anderen Größen in Zusammenhängen steht,
deren Erforschung Aufgabe der Wissenschaft ist. Im Umfeld der Statistik
und Wahrscheinlichkeit werden Größen vorschnell und leichtfertig
als ausschließliche Zufallsgrößen (Zufallsvariablen) aufgefasst,
was sie natürlich nicht sind. Der Zufall ist nur ein Aspekt. Für
Größen gilt daher G = f(F1, F2, ..., Fi,
... Fn), f(Z1, Z2, ..., Zi,
... Zn), wobei F hier kausale, korrelative und Z "zufällige"
Einflüsse bedeuten sollen.
__
Gruppenkennwert > Zur
Problematik Übertragung auf den Einzelfall.
Kennwerte oder Merkmale, die für eine Gruppe (Menge) gelten, gelten
in der Regel nicht für ihre Elemente. Und Merkmale oder Kennwerte,
die für ein Element gelten, gelten in der Regel nicht für die
Gruppe (Menge). Sind 7 SchülerInnen in einer Klasse von 28 SchülerInnen
an Grippe erkrankt, so gilt für eine zufällig herausgegriffene
SchülerIn nicht, dass sie mit einer Wahrscheinlichkeit von p=0.25
oder mit 25% Grippe hat. Denn jedes Element SchülerIn hat entweder
Grippe oder hat keine Grippe. Die Übertragung von Gruppenkennwerten
auf den Einzelfall ist unzulässig, wenngleich ein häufiger Fehler
mit hoher suggestiver Kraft und Ausstrahlung.
__
Gueltigkeitszeitraum
Aussagen gelten in der Regeln nicht absolut (wie z.B. die Lichtgeschwindigkeit),
sondern
nur unter bestimmten Bedingungen (Normalbedingungen,
Normbedingung,
Standardbedingung,
Validität).
Für Statistiken ist das natürliche Referenzdatum das Erhebungsdatum.
Hier stellt sich dann die Frage: wie lange und unter welchen Bedingungen
gelten gelten die Werte zum Zeitpunkt der Erhebung?
__
Häufigkeit := Anzahl von Ereignissen
für einen bestimmten Zeitraum.
__
Heteroskedastizität:
ungleiche, veränderliche Varianz, Inkonstanz der Varianz.
__
Histogramm. Grafische Darstellung von
Häufigkeiten. [W]
__
Homoskedastizität: gleiche
Varianz, Varianz Konstanz
__
Homogenität Allgemein Gleichartigkeit,
rein
Für psychologische Tests erklären Bortz
& Döring (1995), S. 201f: "Homogenität: Die Items
eines eindimensionalen = Instruments stellen Operationalisierungen desselben
Konstrukts dar. Entsprechend ist zu fordern, daß die Items untereinander
[RS: positiv] korrelieren. Die Höhe dieser wechselseitigen Korrelationen
nennt man Homogenität. (Die Auswahl des geeigneten; Korrelationskoeffizienten
hängt auch hier wiederum vom Skalenniveau der Items ab.). Korreliert
man alle k Testitems paarweise miteinander, ergeben sich k*(k-i)/2 Korrelationskoeffizienten
(rii) deren Durchschnitt (r-querii) die Homogenität
des Tests quantifiziert (zur Berechnung einer durchschnittlichen Korrelation
vgl. Bortz, 1993, S. 201). Mittelt man dagegen nur die Korrelationen eines
Items mit allen anderen Items, erhält man die itemspezifische Homogenität.
Bei der Homogenitätsberechnung werden die Autokorrelationen (Korrelation
eines Items mit sich selbst) außer acht gelassen."
Die Homogenitätsforderung ist z.B. im CST-Charakter-Struktur-Test
von Sponsel erfüllt (siehe
bitte hier): Alle Z, H, S und D-Items korrelieren positiv untereinander.
__
Hypothese. Wissenschaftlicher Grundbegriff.
Verwerfungsregel: Eine Hypothese für ein Ergebnis wird verworfen,
wenn bezüglich der Voraussetzungen und Annahmen die Wahrscheinlichkeit
für das Ergebnis kleiner-gleich einer gewählten Schranke (Irrtumswahrscheinlichkeit,
Signifikanzniveau) ist. Das Ergebnis gilt bezüglich der gewählten
Schranke als unwahrscheinlich. Die meisten Hypothesenprüfungen in
der angewandten Statistik prüfen nur virtuelle Möglichkeiten
mit virtuellen Annahmen gegen andere virtuelle Annahmen. Das Zusammenwirkungen
kausaler Faktoren, korrelativer Faktoren und "des Zufalls" ist weitgehend
ungeklärt und wird gewöhnlich nicht erörtert. Die Lehrbücher
sind leer davon.
__
Hypothesendiskussion. Zu
ihr gehören die Erörterung der Hypothesen, ihre Entwicklung und
Begründung, die Prüfmethoden, Voraussetzungen und Annahmen, Formulierung
der Ergebnisse in deutschen Worten, Erörterung der Fehlerarten und
die Möglichkeiten ihrer Abschätzung. Sehr oft kommen inhaltliche
Erörterungen viel zu kurz.
___
Hypothesenraum. > Integratives
Testprinzip, relevanter
Merkmalsraum. Gesamtheit der potentiell relevanten Hypothesen. Eine
vernünftige und realitätsorientierte Statistik muss den gesamten
relevanten Hypothesenraum erfassen und die Hypothesendiskussion realitätsbezogen
darin führen.
__
IMA Integrated Moving Average Modell. > Zeitreihenanalyse.
__
Indifferenzprinzip Wenn keine
Gründe dafür bekannt sind, um eines von verschiedenen möglichen
Ereignissen zu begünstigen, dann sind die Ereignisse als gleich wahrscheinlich
anzusehen. (Carnap & Stegmüller, 1958, S. 3). In der Philosophie
und Wissenschaft auch: Prinzip vom unzureichenden Grund.
__
Identifikationsanalyse
Ein Merkmalsträger soll mit einem Kriteriumsmerkmalsträger
verglichen werden und mit Hilfe eines Vergleichs der Kriteriumsmekrmalsträgergruppe
zugeordnet werden können oder nicht. Im Prinzip das Kernproblem der
Diskriminanzanalyse.
Der Ausdruck wird verwendet von Flury, Bernhard & Riedwyl, Hans (1983)
Identifikationsanalyse. In (99-111): Angewandte multivariate Statistik.
Computergestützte Analyse mehrdimensionaler Daten. Stuttgart: Gustav
Fischer.
- Identifikationsanalyse 99
- Einleitung 99
- Identifikation als Spezialfall der Diskrimination 100
- Die verallgemeinerte Distanzfunktion; Mahalanobis-Distanz 100
- Zusammenhänge zwischen Mahalanobis-Distanz, Identifikationsanalyse, Diskriminanzanalyse und Normalverteilungstheorie 103
- Identifikation einer Banknote 104
- Analyse von Ausreißern und Extremwerten 106
Inferenz, Inferenzstatistik. > statistische Schlussweisen, > schließende Statistik. Schließende, schlußfolgernde Statistik (ergänzend zur deskriptiven, beschreibenden). Zentrale Grundidee und ein Paradigma wahrscheinlichkeitstheoretischer und statistischer Problemlösungen und Aufgaben. Beispiele: Man zieht eine Stichprobe und möchte wissen, wie repräsentativ ist diese Stichprobe für die Grundgesamtheit (Population). Man berechnet einen Wert und möchte wissen, wie gut dieser Wert den unbekannten Parameter schätzt, mit welchen Abweichungen unter diesen oder jenen Annahmen zu rechnen ist? Im Grunde genommen, haben sich Wahrscheinlichkeitstheorie und Statistik in einer eigenen unlösbaren Aufgabe (Aporie) verfangen: Wie gewinnt man Sicherheit (Wissen), wo es keine(s) gibt? Damit ist eine unendliche "Spielwiese" für die mathematische Statistik eröffnet, indem unter "bestimmten" - in Wirklichkeit unbekannten - Annahmen gewisse Annahmen gegenüber anderen Annahmen untersucht und getestet werden. Man bewegt sich weitgehend in virtuellen, fiktiven Welten, obwohl man doch etwas über die Wirklichkeit erfahren möchte. Einen hohen Wert hat allerdings die Mathematik gegenüber allen anderen Wissenschaften: sie zwingt zur Klärung der Voraussetzungen und Annahmen, die ansonsten oft oft leichtfertig und wenig (problem-) bewusst einfach unausgewiesen angenommen werden.
__
Information (Nachricht)
Wissenschaftlicher Grundbegriff. "Energie, Materie und Information stellen die drei wichtigsten Grundbegriffe der Natur- und Ingenieurwissenschaften dar." (Duden Informatik 1993, S. 315)
- Attneave, Fred (dt. 1965, engl. 1959) Informationstheorie in der Psychologie. Grundbegriffe, Techniken, Ergebnisse. 2. d. A. Bern: Huber.
- Haken, Hermann & Haken-Krell, Maria (1989) Entstehung von biologischer Information und Ordnung. Darmstadt: WBG. [Information 37-54]
- Jaglom, A. M. & Jaglom, I. M. (dt. 1967, russ. 1960) Wahrscheinlichkeit und Information. 3. ber. A. Berlin: VEB d Wiss. [Informationsbegriff S. 85-107.
- Seiffert, Helmut (1968) Information über die Information. München: C.H. Beck.
Informationstheorie (Nachrichtentheorie)
1948 von Shannon begründet, die sich mit der strukturellen und quantitativen Erfassung von Information, ihrer Speicherung und Übertragung befasst. Werden k Abfragen benötigt, um eine Information zu finden, wird der Informationswert k zugeordnet.
__
Integratives Testprinzip. > Hypothesenraum. Es geht von der Annahme aus, das ein empirisch erhaltener Datensatz mehr oder minder repräsentativ für die Population ist. Für eine Gesamtbeurteilung sind mehrere hypothetische Betrachtungen sinnvoll und notwendig. Das bloße Testen gegen eine Hypothese, gewöhnlich Nullhypothese genannt, Stichprobenwert = Populationswert, erscheint viel zu einseitig, virtuell und viel zu wenig informativ.
__
Inter := zwischen verschiedenen Systemen (inter-individuell).
__
Interpretation statistischer Größen und Ergebnisse > Deutung..., Darstellung..., Signifikanz ...,
Statistische Größen und Ergebnisse werden sehr selten inhaltlich in klaren deutschen Worten interpretiert. Das ist schon Tradition in den Lehrbüchern, die man so gesehen besser Leerbücher nennen sollte.
__
Intra := innerhalb eines Systems (intra-individuell).
__
Inzidenz. Medizinstatistischer, epidemiologischer Begriff. Nach 257Pschyrembel: Anzahl der Neuerkrankungsfälle in einem bestimmten Zeitraum.
__
Inzidenzenrate. Medizinstatistischer, epidemiologischer Begriff. Nach 257Pschyrembel: Anzahl der Neuerkrankungsfälle in einem bestimmten Zeitraum im Verhältnis zur Anzahl der exponierten Personen. Das Psychometrische Wörterbuch (Rasch et al. 1987) führt aus: "I, Zugangs- oder Neuerkrankungsrate heißt die relative Häufigkeit bzw. Wahrscheinlichkeit des Neuauftretens einer bestimmten Krankheit in einem bestimmten Zeitraum bezogen auf den Umfang der Population, aus der die Erkrankungen hervorgingen. Die I. kann man kumulativ, d.h. auf dem ganzen Untersuchungszeitraum bezogen, oder in Form der Inzidenzdichte für einen (kurzen) bestimmten Teilzeitraum betrachten. Die Inzidenzdichte dient zum Studium der Veränderung der I. mit der Zeit, z. B. in Abhängigkeit vom Alter. Die I. wird in > Längsschnittstudien analysiert.
__
IQ. Normierungseinheit der Intelligenzschätzung.
__
Kappa > W. Übereinstimmungsmaß verschiedener Beurteiler oder eines Beurteilers zu verschiedenen Zeiten (Reliabilität), das eine zufällige Übereinstimmung berücksichtigt.
__
Kausalität